- µĄÅĶ¦ł: 2110128 µ¼Ī
- µĆ¦Õł½:

- µØźĶć¬: ÕīŚõ║¼
-

µ¢ćń½ĀÕłåń▒╗
ńżŠÕī║ńēłÕØŚ
- µłæńÜäĶĄäĶ«» ( 0)
- µłæńÜäĶ«║ÕØø ( 86)
- µłæńÜäķŚ«ńŁö ( 6)
ÕŁśµĪŻÕłåń▒╗
- 2017-03 ( 1)
- 2017-02 ( 1)
- 2016-06 ( 2)
- µø┤ÕżÜÕŁśµĪŻ...
µ£Ćµ¢░Ķ»äĶ«║
-
sunzeshan’╝Ü
┬Ā µēŠõ║åÕŠłõ╣ģ’╝īńö©õ║åĶ┐ÖõĖ¬µÅÆõ╗ČĶ¦ŻÕå│ķŚ«ķóśÕĢ”ŃĆéĶ░óĶ░ó
eclipse jetty debug source not found -
xiaosong0112’╝Ü
µé©ÕźĮ’╝īĶ»ĘķŚ«õĖ║õ╗Ćõ╣łĶ”üĶ┐ÖµĀĘĶ«ŠńĮ«Õæó’╝īÕĤńÉåµś»õ╗Ćõ╣ł’╝¤Õ£©ńĮæõĖŖÕŠłÕżÜĶĮ¼ÕĖ¢ķāĮµ▓Īµ£ē ...
mavenńÜäjettyµÅÆõ╗ȵÅÉńż║No Transaction manager foundÕ»╝Ķć┤ÕÉ»ÕŖ©µģóńÜäĶ¦ŻÕå│µ¢╣µ│Ģ -
eimhee’╝Ü
tjzx ÕåÖķüōńĢģµÉ£Ķ░ʵŁī’╝Ühttp://dian168.cc/µēō ...
Google ķĢ£ÕāÅń½ÖµÉ£ķøå -
tjzx’╝Ü
ńĢģµÉ£Ķ░ʵŁī’╝Ühttp://dian168.cc/µēōÕ╝ĆńÜ䵜»ŌĆ£µ£Ćńü½µ║É ...
Google ķĢ£ÕāÅń½ÖµÉ£ķøå -
eimhee’╝Ü
finallygo ÕåÖķüōõĮĀĶ┐ÖÕ▒×õ║Ä"Õż┤ńŚøÕī╗Õż┤ĶäÜńŚøÕī╗ĶäÜ& ...
Ķ¦ŻÕå│linuxõĖŗtoo many fileķŚ«ķóś
┬Ā
LuceneńÜäń┤óÕ╝ĢķćīķØóÕŁśõ║åõ║øõ╗Ćõ╣ł’╝īÕ”éõĮĢÕŁśµöŠńÜä’╝īõ╣¤ÕŹ│LuceneńÜäń┤óÕ╝Ģµ¢ćõ╗ȵĀ╝Õ╝Å’╝īµś»Ķ»╗µćéLuceneµ║Éõ╗ŻńĀüńÜäõĖƵŖŖķÆźÕīÖŃĆé
ÕĮōµłæõ╗¼ń£¤µŁŻĶ┐øÕģźÕł░Luceneµ║Éõ╗ŻńĀüõ╣ŗõĖŁńÜ䵌ČÕĆÖ’╝īµłæõ╗¼õ╝ÜÕÅæńÄ░:
- LuceneńÜäń┤óÕ╝ĢĶ┐ćń©ŗ’╝īÕ░▒µś»µīēńģ¦Õģ©µ¢ćµŻĆń┤óńÜäÕ¤║µ£¼Ķ┐ćń©ŗ’╝īÕ░åÕĆƵÄÆĶĪ©ÕåÖµłÉµŁżµ¢ćõ╗ȵĀ╝Õ╝ÅńÜäĶ┐ćń©ŗŃĆé
- LuceneńÜäµÉ£ń┤óĶ┐ćń©ŗ’╝īÕ░▒µś»µīēńģ¦µŁżµ¢ćõ╗ȵĀ╝Õ╝ÅÕ░åń┤óÕ╝ĢĶ┐øÕÄ╗ńÜäõ┐Īµü»Ķ»╗Õć║µØź’╝īńäČÕÉÄĶ«Īń«Śµ»Åń»ćµ¢ćµĪŻµēōÕłå(score)ńÜäĶ┐ćń©ŗŃĆé
┬Ā
µ£¼µ¢ćĶ»”ń╗åĶ¦ŻĶ»╗õ║åApache Lucene - Index File Formats(http://lucene.apache.org/java/2_9_0/fileformats.html) Ķ┐Öń»ćµ¢ćń½ĀŃĆé
┬Ā
õĖĆŃĆüÕ¤║µ£¼µ”éÕ┐Ą
õĖŗÕøŠÕ░▒µś»Luceneńö¤µłÉńÜäń┤óÕ╝ĢńÜäõĖĆõĖ¬Õ«×õŠŗ’╝Ü

LuceneńÜäń┤óÕ╝Ģń╗ōµ×䵜»µ£ēÕ▒éµ¼Īń╗ōµ×äńÜä’╝īõĖ╗Ķ”üÕłåõ╗źõĖŗÕćĀõĖ¬Õ▒éµ¼Ī
┬Ā
┬Ā
- ń┤óÕ╝Ģ(Index)’╝Ü
- Õ£©LuceneõĖŁõĖĆõĖ¬ń┤óÕ╝Ģµś»µöŠÕ£©õĖĆõĖ¬µ¢ćõ╗ČÕż╣õĖŁńÜäŃĆé
- Õ”éõĖŖÕøŠ’╝īÕÉīõĖƵ¢ćõ╗ČÕż╣õĖŁńÜäµēƵ£ēńÜäµ¢ćõ╗ȵ×䵳ÉõĖĆõĖ¬Luceneń┤óÕ╝ĢŃĆé
- µ«Ą(Segment)’╝Ü
- õĖĆõĖ¬ń┤óÕ╝ĢÕÅ»õ╗źÕīģÕÉ½ÕżÜõĖ¬µ«Ą’╝īµ«ĄõĖĵ«Ąõ╣ŗķŚ┤µś»ńŗ¼ń½ŗńÜä’╝īµĘ╗ÕŖĀµ¢░µ¢ćµĪŻÕÅ»õ╗źńö¤µłÉµ¢░ńÜ䵫Ą’╝īõĖŹÕÉīńÜ䵫ĄÕÅ»õ╗źÕÉłÕ╣ČŃĆé
- Õ”éõĖŖÕøŠ’╝īÕģʵ£ēńøĖÕÉīÕēŹń╝Ƶ¢ćõ╗ČńÜäÕ▒×ÕÉīõĖĆõĖ¬µ«Ą’╝īÕøŠõĖŁÕģ▒õĖżõĖ¬µ«Ą "_0" ÕÆī "_1"ŃĆé
- segments.genÕÆīsegments_5µś»µ«ĄńÜäÕģāµĢ░µŹ«µ¢ćõ╗Č’╝īõ╣¤ÕŹ│Õ«āõ╗¼õ┐ØÕŁśõ║嵫ĄńÜäÕ▒׵Ʀõ┐Īµü»ŃĆé
- µ¢ćµĪŻ(Document)’╝Ü
- µ¢ćµĪŻµś»µłæõ╗¼Õ╗║ń┤óÕ╝ĢńÜäÕ¤║µ£¼ÕŹĢõĮŹ’╝īõĖŹÕÉīńÜäµ¢ćµĪŻµś»õ┐ØÕŁśÕ£©õĖŹÕÉīńÜ䵫ĄõĖŁńÜä’╝īõĖĆõĖ¬µ«ĄÕÅ»õ╗źÕīģÕÉ½ÕżÜń»ćµ¢ćµĪŻŃĆé
- µ¢░µĘ╗ÕŖĀńÜäµ¢ćµĪŻµś»ÕŹĢńŗ¼õ┐ØÕŁśÕ£©õĖĆõĖ¬µ¢░ńö¤µłÉńÜ䵫ĄõĖŁ’╝īķÜÅńØƵ«ĄńÜäÕÉłÕ╣Č’╝īõĖŹÕÉīńÜäµ¢ćµĪŻÕÉłÕ╣ČÕł░ÕÉīõĖĆõĖ¬µ«ĄõĖŁŃĆé
- Õ¤¤(Field)’╝Ü
- õĖĆń»ćµ¢ćµĪŻÕīģÕɽõĖŹÕÉīń▒╗Õ×ŗńÜäõ┐Īµü»’╝īÕÅ»õ╗źÕłåÕ╝Ćń┤óÕ╝Ģ’╝īµ»öÕ”éµĀćķóś’╝īµŚČķŚ┤’╝īµŁŻµ¢ć’╝īõĮ£ĶĆģńŁē’╝īķāĮÕÅ»õ╗źõ┐ØÕŁśÕ£©õĖŹÕÉīńÜäÕ¤¤ķćīŃĆé
- õĖŹÕÉīÕ¤¤ńÜäń┤óÕ╝Ģµ¢╣Õ╝ÅÕÅ»õ╗źõĖŹÕÉī’╝īÕ£©ń£¤µŁŻĶ¦Żµ×ÉÕ¤¤ńÜäÕŁśÕé©ńÜ䵌ČÕĆÖ’╝īµłæõ╗¼õ╝ÜĶ»”ń╗åĶ¦ŻĶ»╗ŃĆé
- Ķ»Ź(Term)’╝Ü
- Ķ»Źµś»ń┤óÕ╝ĢńÜäµ£ĆÕ░ÅÕŹĢõĮŹ’╝īµś»ń╗ÅĶ┐ćĶ»Źµ│ĢÕłåµ×ÉÕÆīĶ»ŁĶ©ĆÕżäńÉåÕÉÄńÜäÕŁŚń¼”õĖ▓ŃĆé
LuceneńÜäń┤óÕ╝Ģń╗ōµ×äõĖŁ’╝īÕŹ│õ┐ØÕŁśõ║åµŁŻÕÉæõ┐Īµü»’╝īõ╣¤õ┐ØÕŁśõ║åÕÅŹÕÉæõ┐Īµü»ŃĆé
µēĆĶ░ōµŁŻÕÉæõ┐Īµü»’╝Ü
- µīēÕ▒éµ¼Īõ┐ØÕŁśõ║åõ╗Äń┤óÕ╝Ģ’╝īõĖĆńø┤Õł░Ķ»ŹńÜäÕīģÕɽÕģ│ń│╗’╝Üń┤óÕ╝Ģ(Index) ŌĆō> µ«Ą(segment) ŌĆō> µ¢ćµĪŻ(Document) ŌĆō> Õ¤¤(Field) ŌĆō> Ķ»Ź(Term)
- õ╣¤ÕŹ│µŁżń┤óÕ╝ĢÕīģÕɽõ║åķéŻõ║øµ«Ą’╝īµ»ÅõĖ¬µ«ĄÕīģÕɽõ║åķéŻõ║øµ¢ćµĪŻ’╝īµ»ÅõĖ¬µ¢ćµĪŻÕīģÕɽõ║åķéŻõ║øÕ¤¤’╝īµ»ÅõĖ¬Õ¤¤ÕīģÕɽõ║åķéŻõ║øĶ»ŹŃĆé
- µŚóńäȵś»Õ▒éµ¼Īń╗ōµ×ä’╝īÕłÖµ»ÅõĖ¬Õ▒éµ¼ĪķāĮõ┐ØÕŁśõ║åµ£¼Õ▒éµ¼ĪńÜäõ┐Īµü»õ╗źÕÅŖõĖŗõĖĆÕ▒éµ¼ĪńÜäÕģāõ┐Īµü»’╝īõ╣¤ÕŹ│Õ▒׵Ʀõ┐Īµü»’╝īµ»öÕ”éõĖƵ£¼õ╗ŗń╗ŹõĖŁÕøĮÕ£░ńÉåńÜäõ╣”’╝īÕ║öĶ»źķ”¢Õģłõ╗ŗń╗ŹõĖŁÕøĮÕ£░ńÉåńÜäµ”éÕåĄ’╝īõ╗źÕÅŖõĖŁÕøĮÕīģÕÉ½ÕżÜÕ░æõĖ¬ń£ü’╝īµ»ÅõĖ¬ń£üõ╗ŗń╗Źµ£¼ń£üńÜäÕ¤║µ£¼µ”éÕåĄÕÅŖÕīģÕÉ½ÕżÜÕ░æõĖ¬ÕĖé’╝īµ»ÅõĖ¬ÕĖéõ╗ŗń╗Źµ£¼ÕĖéńÜäÕ¤║µ£¼µ”éÕåĄÕÅŖÕīģÕÉ½ÕżÜÕ░æõĖ¬ÕÄ┐’╝īµ»ÅõĖ¬ÕÄ┐ÕģĘõĮōõ╗ŗń╗Źµ»ÅõĖ¬ÕÄ┐ńÜäÕģĘõĮōµāģÕåĄŃĆé
- segments_Nõ┐ØÕŁśõ║åµŁżń┤óÕ╝ĢÕīģÕÉ½ÕżÜÕ░æõĖ¬µ«Ą’╝īµ»ÅõĖ¬µ«ĄÕīģÕÉ½ÕżÜÕ░æń»ćµ¢ćµĪŻŃĆé
- XXX.fnmõ┐ØÕŁśõ║åµŁżµ«ĄÕīģÕɽõ║åÕżÜÕ░æõĖ¬Õ¤¤’╝īµ»ÅõĖ¬Õ¤¤ńÜäÕÉŹń¦░ÕÅŖń┤óÕ╝Ģµ¢╣Õ╝ÅŃĆé
- XXX.fdx’╝īXXX.fdtõ┐ØÕŁśõ║åµŁżµ«ĄÕīģÕɽńÜäµēƵ£ēµ¢ćµĪŻ’╝īµ»Åń»ćµ¢ćµĪŻÕīģÕɽõ║åÕżÜÕ░æÕ¤¤’╝īµ»ÅõĖ¬Õ¤¤õ┐ØÕŁśõ║åķéŻõ║øõ┐Īµü»ŃĆé
- XXX.tvx’╝īXXX.tvd’╝īXXX.tvfõ┐ØÕŁśõ║åµŁżµ«ĄÕīģÕÉ½ÕżÜÕ░æµ¢ćµĪŻ’╝īµ»Åń»ćµ¢ćµĪŻÕīģÕɽõ║åÕżÜÕ░æÕ¤¤’╝īµ»ÅõĖ¬Õ¤¤ÕīģÕɽõ║åÕżÜÕ░æĶ»Ź’╝īµ»ÅõĖ¬Ķ»ŹńÜäÕŁŚń¼”õĖ▓’╝īõĮŹńĮ«ńŁēõ┐Īµü»ŃĆé
µēĆĶ░ōÕÅŹÕÉæõ┐Īµü»’╝Ü
- õ┐ØÕŁśõ║åĶ»ŹÕģĖÕł░ÕĆƵÄÆĶĪ©ńÜ䵜ĀÕ░ä’╝ÜĶ»Ź(Term) ŌĆō> µ¢ćµĪŻ(Document)
- Õ”éõĖŖÕøŠ’╝īÕīģÕɽÕÅŹÕÉæõ┐Īµü»ńÜäµ¢ćõ╗ȵ£ē’╝Ü
- XXX.tis’╝īXXX.tiiõ┐ØÕŁśõ║åĶ»ŹÕģĖ(Term Dictionary)’╝īõ╣¤ÕŹ│µŁżµ«ĄÕīģÕɽńÜäµēƵ£ēńÜäĶ»ŹµīēÕŁŚÕģĖķĪ║Õ║ÅńÜäµÄÆÕ║ÅŃĆé
- XXX.frqõ┐ØÕŁśõ║åÕĆƵÄÆĶĪ©’╝īõ╣¤ÕŹ│ÕīģÕɽµ»ÅõĖ¬Ķ»ŹńÜäµ¢ćµĪŻIDÕłŚĶĪ©ŃĆé
- XXX.prxõ┐ØÕŁśõ║åÕĆƵÄÆĶĪ©õĖŁµ»ÅõĖ¬Ķ»ŹÕ£©ÕīģÕɽµŁżĶ»ŹńÜäµ¢ćµĪŻõĖŁńÜäõĮŹńĮ«ŃĆé
┬Ā
Õ£©õ║åĶ¦ŻLuceneń┤óÕ╝ĢńÜäĶ»”ń╗åń╗ōµ×äõ╣ŗÕēŹ’╝īÕģłń£ŗń£ŗLuceneń┤óÕ╝ĢõĖŁńÜäÕ¤║µ£¼µĢ░µŹ«ń▒╗Õ×ŗŃĆé
┬Ā
┬Ā
õ║īŃĆüÕ¤║µ£¼ń▒╗Õ×ŗ
Luceneń┤óÕ╝Ģµ¢ćõ╗ČõĖŁ’╝īńö©õĖĆõĖŗÕ¤║µ£¼ń▒╗Õ×ŗµØźõ┐ØÕŁśõ┐Īµü»’╝Ü
- Byte’╝ܵś»µ£ĆÕ¤║µ£¼ńÜäń▒╗Õ×ŗ’╝īķĢ┐8õĮŹ(bit)ŃĆé
- UInt32’╝Üńö▒4õĖ¬Byteń╗䵳ÉŃĆé
- UInt64’╝Üńö▒8õĖ¬Byteń╗䵳ÉŃĆé
- VInt’╝Ü
- ÕÅśķĢ┐ńÜäµĢ┤µĢ░ń▒╗Õ×ŗ’╝īÕ«āÕÅ»ĶāĮÕīģÕÉ½ÕżÜõĖ¬Byte’╝īÕ»╣õ║ĵ»ÅõĖ¬ByteńÜä8õĮŹ’╝īÕģČõĖŁÕÉÄ7õĮŹĶĪ©ńż║µĢ░ÕĆ╝’╝īµ£Ćķ½ś1õĮŹĶĪ©ńż║µś»ÕÉ”Ķ┐śµ£ēÕÅ”õĖĆõĖ¬Byte’╝ī0ĶĪ©ńż║µ▓Īµ£ē’╝ī1ĶĪ©ńż║µ£ēŃĆé
- ĶČŖÕēŹķØóńÜäByteĶĪ©ńż║µĢ░ÕĆ╝ńÜäõĮÄõĮŹ’╝īĶČŖÕÉÄķØóńÜäByteĶĪ©ńż║µĢ░ÕĆ╝ńÜäķ½śõĮŹŃĆé
- õŠŗÕ”é130Õī¢õĖ║õ║īĶ┐øÕłČõĖ║ 1000, 0010’╝īµĆ╗Õģ▒ķ£ĆĶ”ü8õĮŹ’╝īõĖĆõĖ¬ByteĶĪ©ńż║õĖŹõ║å’╝īÕøĀĶĆīķ£ĆĶ”üõĖżõĖ¬ByteµØźĶĪ©ńż║’╝īń¼¼õĖĆõĖ¬ByteĶĪ©ńż║ÕÉÄ7õĮŹ’╝īÕ╣ČõĖöÕ£©µ£Ćķ½śõĮŹńĮ«1µØźĶĪ©ńż║ÕÉÄķØóĶ┐śµ£ēõĖĆõĖ¬Byte’╝īµēĆõ╗źõĖ║(1) 0000010’╝īń¼¼õ║īõĖ¬ByteĶĪ©ńż║ń¼¼8õĮŹ’╝īÕ╣ČõĖöµ£Ćķ½śõĮŹńĮ«0µØźĶĪ©ńż║ÕÉÄķØóµ▓Īµ£ēÕģČõ╗¢ńÜäByteõ║å’╝īµēĆõ╗źõĖ║(0) 0000001ŃĆé
┬Ā

- Chars’╝ܵś»UTF-8ń╝¢ńĀüńÜäõĖĆń│╗ÕłŚByteŃĆé
- String’╝ÜõĖĆõĖ¬ÕŁŚń¼”õĖ▓ķ”¢Õģłµś»õĖĆõĖ¬VIntµØźĶĪ©ńż║µŁżÕŁŚń¼”õĖ▓ÕīģÕɽńÜäÕŁŚń¼”ńÜäõĖ¬µĢ░’╝īµÄźńØĆõŠ┐µś»UTF-8ń╝¢ńĀüńÜäÕŁŚń¼”Õ║ÅÕłŚCharsŃĆé
õĖēŃĆüÕ¤║µ£¼Ķ¦äÕłÖ
LuceneõĖ║õ║åõĮ┐ńÜäõ┐Īµü»ńÜäÕŁśÕé©ÕŹĀńö©ńÜäń®║ķŚ┤µø┤Õ░Å’╝īĶ«┐ķŚ«ķƤÕ║”µø┤Õ┐½’╝īķććÕÅ¢õ║åõĖĆõ║øńē╣µ«ŖńÜäµŖĆÕʦ’╝īńäČĶĆīÕ£©ń£ŗLuceneµ¢ćõ╗ȵĀ╝Õ╝ÅńÜ䵌ČÕĆÖ’╝īĶ┐Öõ║øµŖĆÕĘ¦ÕŹ┤Õ«╣µśōõĮ┐µłæõ╗¼µä¤Õł░Õø░µāæ’╝īµēĆõ╗źµ£ēÕ┐ģĶ”üµŖŖĶ┐Öõ║øńē╣µ«ŖńÜäµŖĆÕʦĶ¦äÕłÖµÅÉÕÅ¢Õć║µØźõ╗ŗń╗ŹõĖĆõĖŗŃĆé
Õ£©õĖŗõĖŹµēŹ’╝īĶāĪõ╣▒ń╗ÖĶ┐Öõ║øĶ¦äÕłÖĶĄĘõ║åõĖĆõ║øÕÉŹÕŁŚ’╝īµś»õĖ║õ║åµ¢╣õŠ┐ÕÉÄķØóÕ║öńö©Ķ┐Öõ║øĶ¦äÕłÖńÜ䵌ČÕĆÖĶāĮÕż¤ń«ĆÕŹĢ’╝īõĖŹÕ”źõ╣ŗÕżäĶ»ĘÕż¦Õ«ČĶ░ģĶ¦ŻŃĆé
1. ÕēŹń╝ĆÕÉÄń╝ĆĶ¦äÕłÖ(Prefix+Suffix)
LuceneÕ£©ÕÅŹÕÉæń┤óÕ╝ĢõĖŁ’╝īĶ”üõ┐ØÕŁśĶ»ŹÕģĖ(Term Dictionary)ńÜäõ┐Īµü»’╝īµēƵ£ēńÜäĶ»Ź(Term)Õ£©Ķ»ŹÕģĖõĖŁµś»µīēńģ¦ÕŁŚÕģĖķĪ║Õ║ÅĶ┐øĶĪīµÄÆÕłŚńÜä’╝īńäČĶĆīĶ»ŹÕģĖõĖŁÕīģÕɽõ║åµ¢ćµĪŻõĖŁńÜäÕćĀõ╣ĵēƵ£ēńÜäĶ»Ź’╝īÕ╣ČõĖöµ£ēńÜäĶ»ŹĶ┐śµś»ķØ×ÕĖĖńÜäķĢ┐ńÜä’╝īĶ┐ÖµĀĘń┤óÕ╝Ģµ¢ćõ╗Čõ╝ÜķØ×ÕĖĖńÜäÕż¦’╝īµēĆĶ░ōÕēŹń╝ĆÕÉÄń╝ĆĶ¦äÕłÖ’╝īÕŹ│ÕĮōµ¤ÉõĖ¬Ķ»ŹÕÆīÕēŹõĖĆõĖ¬Ķ»Źµ£ēÕģ▒ÕÉīńÜäÕēŹń╝ĆńÜ䵌ČÕĆÖ’╝īÕÉÄķØóńÜäĶ»Źõ╗ģõ╗ģõ┐ØÕŁśÕēŹń╝ĆÕ£©Ķ»ŹõĖŁńÜäÕüÅń¦╗(offset)’╝īõ╗źÕÅŖķÖżÕēŹń╝Ćõ╗źÕż¢ńÜäÕŁŚń¼”õĖ▓(ń¦░õĖ║ÕÉÄń╝Ć)ŃĆé

µ»öÕ”éĶ”üÕŁśÕé©Õ”éõĖŗĶ»Ź:term’╝ītermagancy’╝ītermagant’╝īterminal’╝ī
Õ”éµ×£µīēńģ¦µŁŻÕĖĖµ¢╣Õ╝ÅµØźÕŁśÕé©’╝īķ£ĆĶ”üńÜäń®║ķŚ┤Õ”éõĖŗ’╝Ü
[VInt = 4] [t][e][r][m]’╝ī[VInt = 10][t][e][r][m][a][g][a][n][c][y]’╝ī[VInt = 9][t][e][r][m][a][g][a][n][t]’╝ī[VInt = 8][t][e][r][m][i][n][a][l]
Õģ▒ķ£ĆĶ”ü35õĖ¬Byte.
Õ”éµ×£Õ║öńö©ÕēŹń╝ĆÕÉÄń╝ĆĶ¦äÕłÖ’╝īķ£ĆĶ”üńÜäń®║ķŚ┤Õ”éõĖŗ’╝Ü
[VInt = 4] [t][e][r][m]’╝ī[VInt = 4 (offset)][VInt = 6][a][g][a][n][c][y]’╝ī[VInt = 8 (offset)][VInt = 1][t]’╝ī[VInt = 4(offset)][VInt = 4][i][n][a][l]
Õģ▒ķ£ĆĶ”ü22õĖ¬ByteŃĆé
Õż¦Õż¦ń╝®Õ░Åõ║åÕŁśÕé©ń®║ķŚ┤’╝īÕ░żÕģȵś»Õ£©µīēÕŁŚÕģĖķĪ║Õ║ŵÄÆÕ║ÅńÜäµāģÕåĄõĖŗ’╝īÕēŹń╝ĆńÜäķćŹÕÉłńÄćÕż¦Õż¦µÅÉķ½śŃĆé
2. ÕĘ«ÕĆ╝Ķ¦äÕłÖ(Delta)
Õ£©LuceneńÜäÕÅŹÕÉæń┤óÕ╝ĢõĖŁ’╝īķ£ĆĶ”üõ┐ØÕŁśÕŠłÕżÜµĢ┤Õ×ŗµĢ░ÕŁŚńÜäõ┐Īµü»’╝īµ»öՔ鵢ćµĪŻIDÕÅĘ’╝īµ»öÕ”éĶ»Ź(Term)Õ£©µ¢ćµĪŻõĖŁńÜäõĮŹńĮ«ńŁēńŁēŃĆé
ńö▒õĖŖķØóõ╗ŗń╗Ź’╝īµłæõ╗¼ń¤źķüō’╝īµĢ┤Õ×ŗµĢ░ÕŁŚµś»õ╗źVIntńÜäµĀ╝Õ╝ÅÕŁśÕé©ńÜäŃĆéķÜÅńØƵĢ░ÕĆ╝ńÜäÕó×Õż¦’╝īµ»ÅõĖ¬µĢ░ÕŁŚÕŹĀńö©ńÜäByteńÜäõĖ¬µĢ░õ╣¤ķĆɵĖÉńÜäÕó×ÕżÜŃĆéµēĆĶ░ōÕĘ«ÕĆ╝Ķ¦äÕłÖ(Delta)Õ░▒µś»ÕģłÕÉÄõ┐ØÕŁśõĖżõĖ¬µĢ┤µĢ░ńÜ䵌ČÕĆÖ’╝īÕÉÄķØóńÜäµĢ┤µĢ░õ╗ģõ╗ģõ┐ØÕŁśÕÆīÕēŹķØóµĢ┤µĢ░ńÜäÕĘ«ÕŹ│ÕÅ»ŃĆé

µ»öÕ”éĶ”üÕŁśÕé©Õ”éõĖŗµĢ┤µĢ░’╝Ü16386’╝ī16387’╝ī16388’╝ī16389
Õ”éµ×£µīēńģ¦µŁŻÕĖĖµ¢╣Õ╝ÅµØźÕŁśÕé©’╝īķ£ĆĶ”üńÜäń®║ķŚ┤Õ”éõĖŗ’╝Ü
[(1) 000, 0010][(1) 000, 0000][(0) 000, 0001]’╝ī[(1) 000, 0011][(1) 000, 0000][(0) 000, 0001]’╝ī[(1) 000, 0100][(1) 000, 0000][(0) 000, 0001]’╝ī[(1) 000, 0101][(1) 000, 0000][(0) 000, 0001]
õŠøķ£Ć12õĖ¬ByteŃĆé
Õ”éµ×£Õ║öńö©ÕĘ«ÕĆ╝Ķ¦äÕłÖµØźÕŁśÕé©’╝īķ£ĆĶ”üńÜäń®║ķŚ┤Õ”éõĖŗ’╝Ü
[(1) 000, 0010][(1) 000, 0000][(0) 000, 0001]’╝ī[(0) 000, 0001]’╝ī[(0) 000, 0001]’╝ī[(0) 000, 0001]
Õģ▒ķ£Ć6õĖ¬ByteŃĆé
Õż¦Õż¦ń╝®Õ░Åõ║åÕŁśÕé©ń®║ķŚ┤’╝īĶĆīõĖöµŚĀĶ«║µś»µ¢ćµĪŻID’╝īĶ┐śµś»Ķ»ŹÕ£©µ¢ćµĪŻõĖŁńÜäõĮŹńĮ«’╝īķāĮµś»µīēõ╗ÄÕ░ÅÕł░Õż¦ńÜäķĪ║Õ║Å’╝īķĆɵĖÉÕó×Õż¦ńÜäŃĆé
3. µł¢ńäČĶʤķÜÅĶ¦äÕłÖ(A, B?)
LuceneńÜäń┤óÕ╝Ģń╗ōµ×äõĖŁÕŁśÕ£©Ķ┐ÖµĀĘńÜäµāģÕåĄ’╝īµ¤ÉõĖ¬ÕĆ╝AÕÉÄķØóÕÅ»ĶāĮÕŁśÕ£©µ¤ÉõĖ¬ÕĆ╝B’╝īõ╣¤ÕÅ»ĶāĮõĖŹÕŁśÕ£©’╝īķ£ĆĶ”üõĖĆõĖ¬µĀćÕ┐ŚµØźĶĪ©ńż║ÕÉÄķØ󵜻ÕÉ”ĶʤķÜÅńØĆBŃĆé
õĖĆĶł¼ńÜäµāģÕåĄõĖŗ’╝īÕ£©AÕÉÄķØóµöŠńĮ«õĖĆõĖ¬Byte’╝īõĖ║0ÕłÖÕÉÄķØóõĖŹÕŁśÕ£©B’╝īõĖ║1ÕłÖÕÉÄķØóÕŁśÕ£©B’╝īµł¢ĶĆģ0ÕłÖÕÉÄķØóÕŁśÕ£©B’╝ī1ÕłÖÕÉÄķØóõĖŹÕŁśÕ£©BŃĆé
õĮåĶ┐ÖµĀĘĶ”üµĄ¬Ķ┤╣õĖĆõĖ¬ByteńÜäń®║ķŚ┤’╝īÕģČÕ«×õĖĆõĖ¬BitÕ░▒ÕÅ»õ╗źõ║åŃĆé
Õ£©LuceneõĖŁ’╝īķććÕÅ¢õ╗źõĖŗńÜäµ¢╣Õ╝Å’╝ÜAńÜäÕĆ╝ÕĘ”ń¦╗õĖĆõĮŹ’╝īń®║Õć║µ£ĆÕÉÄõĖĆõĮŹ’╝īõĮ£õĖ║µĀćÕ┐ŚõĮŹ’╝īµØźĶĪ©ńż║ÕÉÄķØ󵜻ÕÉ”ĶʤķÜÅB’╝īµēĆõ╗źÕ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īA/2µś»ń£¤µŁŻńÜäAÕĤµØźńÜäÕĆ╝ŃĆé

Õ”éµ×£ÕÄ╗Ķ»╗Apache Lucene - Index File FormatsĶ┐Öń»ćµ¢ćń½Ā’╝īõ╝ÜÕÅæńÄ░ÕŠłÕżÜń¼”ÕÉłĶ┐Öń¦ŹĶ¦äÕłÖńÜä’╝Ü
- .frqµ¢ćõ╗ČõĖŁńÜäDocDelta[, Freq?]’╝īDocSkip,PayloadLength?
- .prxµ¢ćõ╗ČõĖŁńÜäPositionDelta,Payload? (õĮåõĖŹÕ«īÕģ©µś»’╝īÕ”éõĖŗĶĪ©Õłåµ×É)
┬Ā
ÕĮōńäČĶ┐śµ£ēõĖĆõ║øÕĖ”?ńÜäõĮåõĖŹÕ▒×õ║ĵŁżĶ¦äÕłÖńÜä’╝Ü
- .frqµ¢ćõ╗ČõĖŁńÜäSkipChildLevelPointer?’╝īµś»ÕżÜÕ▒éĶĘ│ĶĘāĶĪ©õĖŁ’╝īµīćÕÉæõĖŗõĖĆÕ▒éĶĪ©ńÜäµīćķÆł’╝īÕĮōńäČÕ”éµ×£µś»µ£ĆÕÉÄõĖĆÕ▒é’╝īµŁżÕĆ╝Õ░▒õĖŹÕŁśÕ£©’╝īõ╣¤õĖŹķ£ĆĶ”üµĀćÕ┐ŚŃĆé
- .tvfµ¢ćõ╗ČõĖŁńÜäPositions?, Offsets?ŃĆé
- Õ£©µŁżń▒╗µāģÕåĄõĖŗ’╝īÕĖ”?ńÜäÕĆ╝µś»ÕÉ”ÕŁśÕ£©’╝īÕ╣ČõĖŹÕÅ¢Õå│õ║ÄÕēŹķØóńÜäÕĆ╝ńÜäµ£ĆÕÉÄõĖĆõĮŹŃĆé
- ĶĆīµś»ÕÅ¢Õå│õ║ÄLuceneńÜ䵤ÉķĪ╣ķģŹńĮ«’╝īÕĮōńäČĶ┐Öõ║øķģŹńĮ«õ╣¤µś»õ┐ØÕŁśÕ£©Luceneń┤óÕ╝Ģµ¢ćõ╗ČõĖŁńÜäŃĆé
- Õ”éPositionÕÆīOffsetµś»ÕÉ”ÕŁśÕé©’╝īÕÅ¢Õå│õ║Ä.fnmµ¢ćõ╗ČõĖŁÕ»╣õ║ĵ»ÅõĖ¬Õ¤¤ńÜäķģŹńĮ«(TermVector.WITH_POSITIONSÕÆīTermVector.WITH_OFFSETS)
┬Ā
õĖ║õ╗Ćõ╣łõ╝ÜÕŁśÕ£©õ╗źõĖŖõĖżń¦ŹµāģÕåĄ’╝īÕģČÕ«×µś»ÕÅ»õ╗źńÉåĶ¦ŻńÜä’╝Ü
- Õ»╣õ║Äń¼”ÕÉłµł¢ńäČĶʤķÜÅĶ¦äÕłÖńÜä’╝īµś»ÕøĀõĖ║Õ»╣õ║ĵ»ÅõĖĆõĖ¬A’╝īBµś»ÕÉ”ÕŁśÕ£©ķāĮõĖŹńøĖÕÉī’╝īÕĮōĶ┐Öń¦ŹµāģÕåĄÕż¦ķćÅÕŁśÕ£©ńÜ䵌ČÕĆÖ’╝īõ╗ÄõĖĆõĖ¬ByteÕł░õĖĆõĖ¬BitÕ”éµŁż8ÕĆŹńÜäń®║ķŚ┤ĶŖéń║”Ķ┐śµś»ÕŠłÕĆ╝ÕŠŚńÜäŃĆé
- Õ»╣õ║ÄõĖŹń¼”ÕÉłµł¢ńäČĶʤķÜÅĶ¦äÕłÖńÜä’╝īµś»ÕøĀõĖ║µ¤ÉõĖ¬ÕĆ╝ńÜ䵜»ÕÉ”ÕŁśÕ£©ńÜäķģŹńĮ«Õ»╣õ║ĵĢ┤õĖ¬Õ¤¤(Field)ńöÜĶć│µĢ┤õĖ¬ń┤óÕ╝ĢķāĮµś»µ£ēµĢłńÜä’╝īĶĆīķØ×µ»Åµ¼ĪńÜäµāģÕåĄķāĮõĖŹńøĖÕÉī’╝īÕøĀĶĆīÕÅ»õ╗źń╗¤õĖĆÕŁśµöŠõĖĆõĖ¬µĀćÕ┐ŚŃĆé
| µ¢ćń½ĀõĖŁÕ»╣Õ”éõĖŗµĀ╝Õ╝ÅńÜäµÅÅĶ┐░õ╗żõ║║Õø░µāæ’╝Ü
┬Ā Positions --> <PositionDelta,Payload?> Freq Payload --> <PayloadLength?,PayloadData> PositionDeltaÕÆīPayloadµś»ÕÉ”ķĆéńö©µł¢ńäČĶʤķÜÅĶ¦äÕłÖÕæó’╝¤Õ”éõĮĢµĀćĶ»åPayloadLengthµś»ÕÉ”ÕŁśÕ£©Õæó’╝¤ ÕģČÕ«×PositionDeltaÕÆīPayloadÕ╣ČõĖŹń¼”ÕÉłµł¢ńäČĶʤķÜÅĶ¦äÕłÖ’╝īPayloadµś»ÕÉ”ÕŁśÕ£©’╝īµś»ńö▒.fnmµ¢ćõ╗ČõĖŁÕ»╣õ║ĵ»ÅõĖ¬Õ¤¤ńÜäķģŹńĮ«õĖŁµ£ēÕģ│PayloadńÜäķģŹńĮ«Õå│Õ«ÜńÜä(FieldOption.STORES_PAYLOADS) ŃĆé ÕĮōPayloadõĖŹÕŁśÕ£©µŚČ’╝īPayloadDeltaµ£¼Ķ║½õĖŹķüĄõ╗ĵł¢ńäČĶʤķÜÅÕÄ¤ÕłÖŃĆé ÕĮōPayloadÕŁśÕ£©µŚČ’╝īµĀ╝Õ╝ÅÕ║öĶ»źÕÅśµłÉÕ”éõĖŗ’╝ÜPositions --> <PositionDelta,PayloadLength?,PayloadData> Freq õ╗ÄĶĆīPositionDeltaÕÆīPayloadLengthõĖĆĶĄĘķĆéńö©µł¢ńäČĶʤķÜÅĶ¦äÕłÖŃĆé |
┬Ā
┬Ā
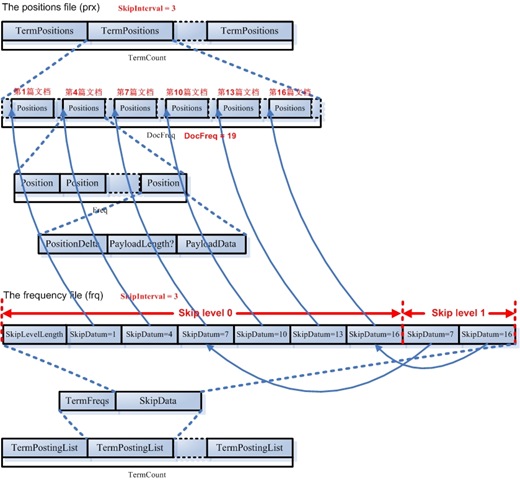
4. ĶĘ│ĶĘāĶĪ©Ķ¦äÕłÖ(Skip list)┬Ā
õĖ║õ║åµÅÉķ½śµ¤źµēŠńÜäµĆ¦ĶāĮ’╝īLuceneÕ£©ÕŠłÕżÜÕ£░µ¢╣ķććÕÅ¢ńÜäĶĘ│ĶĘāĶĪ©ńÜäµĢ░µŹ«ń╗ōµ×äŃĆé
ĶĘ│ĶĘāĶĪ©(Skip List)µś»Õ”éÕøŠńÜäõĖĆń¦ŹµĢ░µŹ«ń╗ōµ×ä’╝īµ£ēõ╗źõĖŗÕćĀõĖ¬Õ¤║µ£¼ńē╣ÕŠü’╝Ü
- Õģāń┤Āµś»µīēķĪ║Õ║ŵÄÆÕłŚńÜä’╝īÕ£©LuceneõĖŁ’╝īµł¢µś»µīēÕŁŚÕģĖķĪ║Õ║ŵÄÆÕłŚ’╝īµł¢µś»µīēõ╗ÄÕ░ÅÕł░Õż¦ķĪ║Õ║ŵÄÆÕłŚŃĆé
- ĶĘ│ĶĘāµś»µ£ēķŚ┤ķÜöńÜä(Interval)’╝īõ╣¤ÕŹ│µ»Åµ¼ĪĶĘ│ĶĘāńÜäÕģāń┤ĀµĢ░’╝īķŚ┤ķÜöµś»õ║ŗÕģłķģŹńĮ«ÕźĮńÜä’╝īÕ”éÕøŠĶĘ│ĶĘāĶĪ©ńÜäķŚ┤ķÜöõĖ║3ŃĆé
- ĶĘ│ĶĘāĶĪ©µś»ńö▒Õ▒éµ¼ĪńÜä(level)’╝īµ»ÅõĖĆÕ▒éńÜäµ»ÅķÜöµīćÕ«ÜķŚ┤ķÜöńÜäÕģāń┤Āµ×䵳ÉõĖŖõĖĆÕ▒é’╝īÕ”éÕøŠĶĘ│ĶĘāĶĪ©Õģ▒µ£ē2Õ▒éŃĆé
┬Ā

ķ£ĆĶ”üµ│©µäÅõĖĆńé╣ńÜ䵜»’╝īÕ£©ÕŠłÕżÜµĢ░µŹ«ń╗ōµ×䵳¢ń«Śµ│Ģõ╣”õĖŁķāĮõ╝ܵ£ēĶĘ│ĶĘāĶĪ©ńÜäµÅÅĶ┐░’╝īÕĤńÉåķāĮµś»Õż¦Ķć┤ńøĖÕÉīńÜä’╝īõĮåµś»Õ«Üõ╣ēń©Źµ£ēÕĘ«Õł½’╝Ü
- Õ»╣ķŚ┤ķÜö(Interval)ńÜäÕ«Üõ╣ē’╝Ü Õ”éÕøŠõĖŁ’╝īµ£ēńÜäĶ«żõĖ║ķŚ┤ķÜöõĖ║2’╝īÕŹ│õĖżõĖ¬õĖŖÕ▒éÕģāń┤Āõ╣ŗķŚ┤ńÜäÕģāń┤ĀµĢ░’╝īõĖŹÕīģµŗ¼õĖżõĖ¬õĖŖÕ▒éÕģāń┤Ā’╝øµ£ēńÜäĶ«żõĖ║µś»3’╝īÕŹ│õĖżõĖ¬õĖŖÕ▒éÕģāń┤Āõ╣ŗķŚ┤ńÜäÕĘ«’╝īÕīģµŗ¼ÕÉÄķØóõĖŖÕ▒éÕģāń┤Ā’╝īõĖŹÕīģµŗ¼ÕēŹķØóńÜäõĖŖÕ▒éÕģāń┤Ā’╝øµ£ēńÜäĶ«żõĖ║µś»4’╝īÕŹ│ķÖżõĖżõĖ¬õĖŖÕ▒éÕģāń┤Āõ╣ŗķŚ┤ńÜäÕģāń┤ĀÕż¢’╝īµŚóÕīģµŗ¼ÕēŹķØó’╝īõ╣¤Õīģµŗ¼ÕÉÄķØóńÜäõĖŖÕ▒éÕģāń┤ĀŃĆéLuceneµś»ķććÕÅ¢ńÜäń¼¼õ║īń¦ŹÕ«Üõ╣ēŃĆé
- Õ»╣Õ▒éµ¼Ī(Level)ńÜäÕ«Üõ╣ē’╝ÜÕ”éÕøŠõĖŁ’╝īµ£ēńÜäĶ«żõĖ║Õ║öĶ»źÕīģµŗ¼ÕĤķōŠĶĪ©Õ▒é’╝īÕ╣Čõ╗Ä1Õ╝ĆÕ¦ŗĶ«ĪµĢ░’╝īÕłÖµĆ╗Õ▒éµ¼ĪõĖ║3’╝īõĖ║1’╝ī2’╝ī3Õ▒é’╝øµ£ēńÜäĶ«żõĖ║Õ║öĶ»źÕīģµŗ¼ÕĤķōŠĶĪ©Õ▒é’╝īÕ╣Čõ╗Ä0Ķ«ĪµĢ░’╝īõĖ║0’╝ī1’╝ī2Õ▒é’╝øµ£ēńÜäĶ«żõĖ║õĖŹÕ║öĶ»źÕīģµŗ¼ÕĤķōŠĶĪ©Õ▒é’╝īõĖöõ╗Ä1Õ╝ĆÕ¦ŗĶ«ĪµĢ░’╝īÕłÖõĖ║1’╝ī2Õ▒é’╝øµ£ēńÜäĶ«żõĖ║õĖŹÕ║öĶ»źÕīģµŗ¼ķōŠĶĪ©Õ▒é’╝īõĖöõ╗Ä0Õ╝ĆÕ¦ŗĶ«ĪµĢ░’╝īÕłÖõĖ║0’╝ī1Õ▒éŃĆéLuceneķććÕÅ¢ńÜ䵜»µ£ĆÕÉÄõĖĆń¦ŹÕ«Üõ╣ēŃĆé
┬Ā
ĶĘ│ĶĘāĶĪ©µ»öķĪ║Õ║ŵ¤źµēŠ’╝īÕż¦Õż¦µÅÉķ½śõ║嵤źµēŠķƤÕ║”’╝īՔ鵤źµēŠÕģāń┤Ā72’╝īÕĤµØźĶ”üĶ«┐ķŚ«2’╝ī3’╝ī7’╝ī12’╝ī23’╝ī37’╝ī39’╝ī44’╝ī50’╝ī72µĆ╗Õģ▒10õĖ¬Õģāń┤Ā’╝īÕ║öńö©ĶĘ│ĶĘāĶĪ©ÕÉÄ’╝īÕŬĶ”üķ”¢ÕģłĶ«┐ķŚ«ń¼¼1Õ▒éńÜä50’╝īÕÅæńÄ░72Õż¦õ║Ä50’╝īĶĆīń¼¼1Õ▒鵌ĀõĖŗõĖĆõĖ¬ĶŖéńé╣’╝īńäČÕÉÄĶ«┐ķŚ«ń¼¼2Õ▒éńÜä94’╝īÕÅæńÄ░94Õż¦õ║Ä72’╝īńäČÕÉÄĶ«┐ķŚ«ÕĤķōŠĶĪ©ńÜä72’╝īµēŠÕł░Õģāń┤Ā’╝īÕģ▒ķ£ĆĶ”üĶ«┐ķŚ«3õĖ¬Õģāń┤ĀÕŹ│ÕÅ»ŃĆé
ńäČĶĆīLuceneÕ£©ÕģĘõĮōÕ«×ńÄ░õĖŖ’╝īõĖÄńÉåĶ«║ÕÅłµ£ēµēĆõĖŹÕÉī’╝īÕ£©ÕģĘõĮōńÜäµĀ╝Õ╝ÅõĖŁ’╝īõ╝ÜĶ»”ń╗åĶ»┤µśÄŃĆé
┬Ā
┬Ā
LuceneµĆ╗ńÜäµØźĶ»┤µś»’╝Ü
- õĖĆõĖ¬ķ½śµĢłńÜä’╝īÕÅ»µē®Õ▒ĢńÜä’╝īÕģ©µ¢ćµŻĆń┤óÕ║ōŃĆé
- Õģ©ķā©ńö©JavaÕ«×ńÄ░’╝īµŚĀķĪ╗ķģŹńĮ«ŃĆé
- õ╗ģµö»µīüń║»µ¢ćµ£¼µ¢ćõ╗ČńÜäń┤óÕ╝Ģ(Indexing)ÕÆīµÉ£ń┤ó(Search)ŃĆé
- õĖŹĶ┤¤Ķ┤Żńö▒ÕģČõ╗¢µĀ╝Õ╝ÅńÜäµ¢ćõ╗ȵŖĮÕÅ¢ń║»µ¢ćµ£¼µ¢ćõ╗Č’╝īµł¢õ╗ÄńĮæń╗£õĖŁµŖōÕÅ¢µ¢ćõ╗ČńÜäĶ┐ćń©ŗŃĆé
┬Ā
Õ£©Lucene in actionõĖŁ’╝īLucene ńÜäµ×äµ×ČÕÆīĶ┐ćń©ŗÕ”éõĖŗÕøŠ’╝ī

Ķ»┤µśÄLuceneµś»µ£ēń┤óÕ╝ĢÕÆīµÉ£ń┤óńÜäõĖżõĖ¬Ķ┐ćń©ŗ’╝īÕīģÕɽń┤óÕ╝ĢÕłøÕ╗║’╝īń┤óÕ╝Ģ’╝īµÉ£ń┤óõĖēõĖ¬Ķ”üńé╣ŃĆé
Ķ«®µłæõ╗¼µø┤ń╗åõĖĆõ║øń£ŗLuceneńÜäÕÉäń╗äõ╗Č’╝Ü

- Ķó½ń┤óÕ╝ĢńÜäµ¢ćµĪŻńö©DocumentÕ»╣Ķ▒ĪĶĪ©ńż║ŃĆé
- IndexWriterķĆÜĶ┐ćÕćĮµĢ░addDocumentÕ░åµ¢ćµĪŻµĘ╗ÕŖĀÕł░ń┤óÕ╝ĢõĖŁ’╝īÕ«×ńÄ░ÕłøÕ╗║ń┤óÕ╝ĢńÜäĶ┐ćń©ŗŃĆé
- LuceneńÜäń┤óÕ╝Ģµś»Õ║öńö©ÕÅŹÕÉæń┤óÕ╝ĢŃĆé
- ÕĮōńö©µłĘµ£ēĶ»Ęµ▒鵌Ȓ╝īQueryõ╗ŻĶĪ©ńö©µłĘńÜ䵤źĶ»óĶ»ŁÕÅźŃĆé
- IndexSearcherķĆÜĶ┐ćÕćĮµĢ░searchµÉ£ń┤óLucene IndexŃĆé
- IndexSearcherĶ«Īń«Śterm weightÕÆīscoreÕ╣ČõĖöÕ░åń╗ōµ×£Ķ┐öÕø×ń╗Öńö©µłĘŃĆé
- Ķ┐öÕø×ń╗Öńö©µłĘńÜäµ¢ćµĪŻķøåÕÉłńö©TopDocsCollectorĶĪ©ńż║ŃĆé
┬Ā
┬Ā
ķéŻõ╣łÕ”éõĮĢÕ║öńö©Ķ┐Öõ║øń╗äõ╗ČÕæó’╝¤
Ķ«®µłæõ╗¼ÕåŹĶ»”ń╗åÕł░Õ»╣Lucene API ńÜäĶ░āńö©Õ«×ńÄ░ń┤óÕ╝ĢÕÆīµÉ£ń┤óĶ┐ćń©ŗŃĆé

- ń┤óÕ╝ĢĶ┐ćń©ŗÕ”éõĖŗ’╝Ü
- ÕłøÕ╗║õĖĆõĖ¬IndexWriterńö©µØźÕåÖń┤óÕ╝Ģµ¢ćõ╗Č’╝īÕ«āµ£ēÕćĀõĖ¬ÕÅéµĢ░’╝īINDEX_DIRÕ░▒µś»ń┤óÕ╝Ģµ¢ćõ╗ȵēĆÕŁśµöŠńÜäõĮŹńĮ«’╝īAnalyzerõŠ┐µś»ńö©µØźÕ»╣µ¢ćµĪŻĶ┐øĶĪīĶ»Źµ│ĢÕłåµ×ÉÕÆīĶ»ŁĶ©ĆÕżäńÉåńÜäŃĆé
- ÕłøÕ╗║õĖĆõĖ¬Documentõ╗ŻĶĪ©µłæõ╗¼Ķ”üń┤óÕ╝ĢńÜäµ¢ćµĪŻŃĆé
- Õ░åõĖŹÕÉīńÜäFieldÕŖĀÕģźÕł░µ¢ćµĪŻõĖŁŃĆ鵳æõ╗¼ń¤źķüō’╝īõĖĆń»ćµ¢ćµĪŻµ£ēÕżÜń¦Źõ┐Īµü»’╝īÕ”éķóśńø«’╝īõĮ£ĶĆģ’╝īõ┐«µö╣µŚČķŚ┤’╝īÕåģÕ«╣ńŁēŃĆéõĖŹÕÉīń▒╗Õ×ŗńÜäõ┐Īµü»ńö©õĖŹÕÉīńÜäFieldµØźĶĪ©ńż║’╝īÕ£©µ£¼õŠŗÕŁÉõĖŁ’╝īõĖĆÕģ▒µ£ēõĖżń▒╗õ┐Īµü»Ķ┐øĶĪīõ║åń┤óÕ╝Ģ’╝īõĖĆõĖ¬µś»µ¢ćõ╗ČĶĘ»ÕŠä’╝īõĖĆõĖ¬µś»µ¢ćõ╗ČÕåģÕ«╣ŃĆéÕģČõĖŁFileReaderńÜäSRC_FILEÕ░▒ĶĪ©ńż║Ķ”üń┤óÕ╝ĢńÜäµ║ɵ¢ćõ╗ČŃĆé
- IndexWriterĶ░āńö©ÕćĮµĢ░addDocumentÕ░åń┤óÕ╝ĢÕåÖÕł░ń┤óÕ╝Ģµ¢ćõ╗ČÕż╣õĖŁŃĆé
- µÉ£ń┤óĶ┐ćń©ŗÕ”éõĖŗ’╝Ü
- IndexReaderÕ░åńŻüńøśõĖŖńÜäń┤óÕ╝Ģõ┐Īµü»Ķ»╗ÕģźÕł░ÕåģÕŁś’╝īINDEX_DIRÕ░▒µś»ń┤óÕ╝Ģµ¢ćõ╗ČÕŁśµöŠńÜäõĮŹńĮ«ŃĆé
- ÕłøÕ╗║IndexSearcherÕćåÕżćĶ┐øĶĪīµÉ£ń┤óŃĆé
- ÕłøÕ╗║Analyerńö©µØźÕ»╣µ¤źĶ»óĶ»ŁÕÅźĶ┐øĶĪīĶ»Źµ│ĢÕłåµ×ÉÕÆīĶ»ŁĶ©ĆÕżäńÉåŃĆé
- ÕłøÕ╗║QueryParserńö©µØźÕ»╣µ¤źĶ»óĶ»ŁÕÅźĶ┐øĶĪīĶ»Łµ│ĢÕłåµ×ÉŃĆé
- QueryParserĶ░āńö©parserĶ┐øĶĪīĶ»Łµ│ĢÕłåµ×É’╝īÕĮóµłÉµ¤źĶ»óĶ»Łµ│ĢµĀæ’╝īµöŠÕł░QueryõĖŁŃĆé
- IndexSearcherĶ░āńö©searchÕ»╣µ¤źĶ»óĶ»Łµ│ĢµĀæQueryĶ┐øĶĪīµÉ£ń┤ó’╝īÕŠŚÕł░ń╗ōµ×£TopScoreDocCollectorŃĆé
┬Ā
õ╗źõĖŖõŠ┐µś»Lucene APIÕćĮµĢ░ńÜäń«ĆÕŹĢĶ░āńö©ŃĆé
ńäČĶĆīÕĮōĶ┐øÕģźLuceneńÜäµ║Éõ╗ŻńĀüÕÉÄ’╝īÕÅæńÄ░Luceneµ£ēÕŠłÕżÜÕīģ’╝īÕģ│ń│╗ķöÖń╗╝ÕżŹµØéŃĆé
ńäČĶĆīķĆÜĶ┐ćõĖŗÕøŠ’╝īµłæõ╗¼õĖŹķÜŠÕÅæńÄ░’╝īLuceneńÜäÕÉäµ║ÉńĀüµ©ĪÕØŚ’╝īķāĮµś»Õ»╣µÖ«ķĆÜń┤óÕ╝ĢÕÆīµÉ£ń┤óĶ┐ćń©ŗńÜäõĖĆń¦ŹÕ«×ńÄ░ŃĆé
µŁżÕøŠµś»õĖŖõĖĆĶŖéõ╗ŗń╗ŹńÜäÕģ©µ¢ćµŻĆń┤óńÜ䵥üń©ŗÕ»╣Õ║öńÜäLuceneÕ«×ńÄ░ńÜäÕīģń╗ōµ×äŃĆé(ÕÅéńģ¦http://www.lucene.com.cn/about.htmõĖŁµ¢ćń½ĀŃĆŖÕ╝ƵöŠµ║Éõ╗ŻńĀüńÜäÕģ©µ¢ćµŻĆń┤óÕ╝ĢµōÄLuceneŃĆŗ)

- LuceneńÜäanalysisµ©ĪÕØŚõĖ╗Ķ”üĶ┤¤Ķ┤ŻĶ»Źµ│ĢÕłåµ×ÉÕÅŖĶ»ŁĶ©ĆÕżäńÉåĶĆīÕĮóµłÉTermŃĆé
- LuceneńÜäindexµ©ĪÕØŚõĖ╗Ķ”üĶ┤¤Ķ┤Żń┤óÕ╝ĢńÜäÕłøÕ╗║’╝īķćīķØóµ£ēIndexWriterŃĆé
- LuceneńÜästoreµ©ĪÕØŚõĖ╗Ķ”üĶ┤¤Ķ┤Żń┤óÕ╝ĢńÜäĶ»╗ÕåÖŃĆé
- LuceneńÜäQueryParserõĖ╗Ķ”üĶ┤¤Ķ┤ŻĶ»Łµ│ĢÕłåµ×ÉŃĆé
- LuceneńÜäsearchµ©ĪÕØŚõĖ╗Ķ”üĶ┤¤Ķ┤ŻÕ»╣ń┤óÕ╝ĢńÜäµÉ£ń┤óŃĆé
- LuceneńÜäsimilarityµ©ĪÕØŚõĖ╗Ķ”üĶ┤¤Ķ┤ŻÕ»╣ńøĖÕģ│µĆ¦µēōÕłåńÜäÕ«×ńÄ░ŃĆé
┬Ā
õ║åĶ¦Żõ║åLuceneńÜäµĢ┤õĖ¬ń╗ōµ×ä’╝īµłæõ╗¼õŠ┐ÕÅ»õ╗źÕ╝ĆÕ¦ŗLuceneńÜäµ║ÉńĀüõ╣ŗµŚģõ║åŃĆé
┬Ā
┬Ā
ÕøøŃĆüÕģĘõĮōµĀ╝Õ╝Å
õĖŖķØóµøŠń╗Åõ║żõ╗ŻĶ┐ć’╝īLuceneõ┐ØÕŁśõ║åõ╗ÄIndexÕł░SegmentÕł░DocumentÕł░FieldõĖĆńø┤Õł░TermńÜ䵣ŻÕÉæõ┐Īµü»’╝īõ╣¤Õīģµŗ¼õ║åõ╗ÄTermÕł░DocumentµśĀÕ░äńÜäÕÅŹÕÉæõ┐Īµü»’╝īĶ┐śµ£ēÕģČõ╗¢õĖĆõ║øLuceneńē╣µ£ēńÜäõ┐Īµü»ŃĆéõĖŗķØóÕ»╣Ķ┐ÖõĖēń¦Źõ┐Īµü»õĖĆõĖĆõ╗ŗń╗ŹŃĆé
4.1. µŁŻÕÉæõ┐Īµü»
Index ŌĆō> Segments (segments.gen, segments_N) ŌĆō> Field(fnm, fdx, fdt) ŌĆō> Term (tvx, tvd, tvf)
õĖŖķØóńÜäÕ▒éµ¼Īń╗ōµ×äõĖŹµś»ÕŹüÕłåńÜäÕćåńĪ«’╝īÕøĀõĖ║segments.genÕÆīsegments_Nõ┐ØÕŁśńÜ䵜»µ«Ą(segment)ńÜäÕģāµĢ░µŹ«õ┐Īµü»(metadata)’╝īÕģČÕ«×µś»µ»ÅõĖ¬IndexõĖĆõĖ¬ńÜä’╝īĶĆīµ«ĄńÜäń£¤µŁŻńÜäµĢ░µŹ«õ┐Īµü»’╝īµś»õ┐ØÕŁśÕ£©Õ¤¤(Field)ÕÆīĶ»Ź(Term)õĖŁńÜäŃĆé
4.1.1. µ«ĄńÜäÕģāµĢ░µŹ«õ┐Īµü»(segments_N)
õĖĆõĖ¬ń┤óÕ╝Ģ(Index)ÕÅ»õ╗źÕÉīµŚČÕŁśÕ£©ÕżÜõĖ¬segments_N(Ķć│õ║ÄÕ”éõĮĢÕŁśÕ£©ÕżÜõĖ¬segments_N’╝īÕ£©µÅÅĶ┐░Õ«īĶ»”ń╗åõ┐Īµü»õ╣ŗÕÉÄõ╝ÜõĖŠõŠŗĶ»┤µśÄ)’╝īńäČĶĆīÕĮōµłæõ╗¼Ķ”üµēōÕ╝ĆõĖĆõĖ¬ń┤óÕ╝ĢńÜ䵌ČÕĆÖ’╝īµłæõ╗¼Õ┐ģķĪ╗Ķ”üķĆēµŗ®õĖĆõĖ¬µØźµēōÕ╝Ć’╝īķéŻÕ”éõĮĢķĆēµŗ®Õō¬õĖ¬segments_NÕæó’╝¤
LuceneķććÕÅ¢õ╗źõĖŗĶ┐ćń©ŗ’╝Ü
- ÕģČõĖĆ’╝īÕ£©µēƵ£ēńÜäsegments_NõĖŁķĆēµŗ®Nµ£ĆÕż¦ńÜäõĖĆõĖ¬ŃĆéÕ¤║µ£¼ķĆ╗ĶŠæÕÅéńģ¦SegmentInfos.getCurrentSegmentGeneration(File[] files)’╝īÕģČÕ¤║µ£¼µĆØĶĘ»Õ░▒µś»Õ£©µēƵ£ēõ╗źsegmentsÕ╝ĆÕż┤’╝īÕ╣ČõĖöõĖŹµś»segments.genńÜäµ¢ćõ╗ČõĖŁ’╝īķĆēµŗ®Nµ£ĆÕż¦ńÜäõĖĆõĖ¬õĮ£õĖ║genAŃĆé
- ÕģČõ║ī’╝īµēōÕ╝Ćsegments.gen’╝īÕģČõĖŁõ┐ØÕŁśõ║åÕĮōÕēŹńÜäNÕĆ╝ŃĆéÕģȵĀ╝Õ╝ÅÕ”éõĖŗ’╝īĶ»╗Õć║ńēłµ£¼ÕÅĘ(Version)’╝īńäČÕÉÄÕåŹĶ»╗Õć║õĖżõĖ¬N’╝īÕ”éµ×£õĖżĶĆģńøĖńŁē’╝īÕłÖõĮ£õĖ║genBŃĆé
-

┬Ā
IndexInput genInput = directory.openInput(IndexFileNames.SEGMENTS_GEN);//"segments.gen"
int version = genInput.readInt();//Ķ»╗Õć║ńēłµ£¼ÕÅĘ
if (version == FORMAT_LOCKLESS) {//Õ”éµ×£ńēłµ£¼ÕÅʵŁŻńĪ«
┬Ā┬Ā┬Ā long gen0 = genInput.readLong();//Ķ»╗Õć║ń¼¼õĖĆõĖ¬N
┬Ā┬Ā┬Ā long gen1 = genInput.readLong();//Ķ»╗Õć║ń¼¼õ║īõĖ¬N
┬Ā┬Ā┬Ā if (gen0 == gen1) {//Õ”éµ×£õĖżĶĆģńøĖńŁēÕłÖõĖ║genB
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā genB = gen0;
┬Ā┬Ā┬Ā }
}
- ÕģČõĖē’╝īÕ£©õĖŖĶ┐░ÕŠŚÕł░ńÜägenAÕÆīgenBõĖŁķĆēµŗ®µ£ĆÕż¦ńÜäķéŻõĖ¬õĮ£õĖ║ÕĮōÕēŹńÜäN’╝īµ¢╣µēŹµēōÕ╝Ćsegments_Nµ¢ćõ╗ČŃĆéÕģČÕ¤║µ£¼ķĆ╗ĶŠæÕ”éõĖŗ’╝Ü
┬Ā
if (genA > genB)
┬Ā┬Ā┬Ā gen = genA;
else
┬Ā┬Ā┬Ā gen = genB;

┬Ā
┬Ā
Õ”éõĖŗÕøŠµś»segments_NńÜäÕģĘõĮōµĀ╝Õ╝Å’╝Ü

- Format’╝Ü
- ń┤óÕ╝Ģµ¢ćõ╗ȵĀ╝Õ╝ÅńÜäńēłµ£¼ÕÅĘŃĆé
- ńö▒õ║ÄLuceneµś»Õ£©õĖŹµ¢ŁÕ╝ĆÕÅæĶ┐ćń©ŗõĖŁńÜä’╝īÕøĀĶĆīõĖŹÕÉīńēłµ£¼ńÜäLucene’╝īÕģČń┤óÕ╝Ģµ¢ćõ╗ȵĀ╝Õ╝Åõ╣¤õĖŹÕ░ĮńøĖÕÉī’╝īõ║ĵś»Ķ¦äÕ«ÜõĖĆõĖ¬ńēłµ£¼ÕÅĘŃĆé
- Lucene 2.1µŁżÕĆ╝-3’╝īLucene 2.9µŚČ’╝īµŁżÕĆ╝õĖ║-9ŃĆé
- ÕĮōńö©µ¤ÉõĖ¬ńēłµ£¼ÕÅĘńÜäIndexReaderĶ»╗ÕÅ¢ÕÅ”õĖĆõĖ¬ńēłµ£¼ÕÅĘńö¤µłÉńÜäń┤óÕ╝ĢńÜ䵌ČÕĆÖ’╝īõ╝ÜÕøĀõĖ║µŁżÕĆ╝õĖŹÕÉīĶĆīµŖźķöÖŃĆé
- Version’╝Ü
- ń┤óÕ╝ĢńÜäńēłµ£¼ÕÅĘ’╝īĶ«░ÕĮĢõ║åIndexWriterÕ░åõ┐«µö╣µÅÉõ║żÕł░ń┤óÕ╝Ģµ¢ćõ╗ČõĖŁńÜäµ¼ĪµĢ░ŃĆé
- ÕģČÕłØÕ¦ŗÕĆ╝Õż¦ÕżÜµĢ░µāģÕåĄõĖŗõ╗Äń┤óÕ╝Ģµ¢ćõ╗ČķćīķØóĶ»╗Õć║’╝īõ╗ģõ╗ģÕ£©ń┤óÕ╝ĢÕ╝ĆÕ¦ŗÕłøÕ╗║ńÜ䵌ČÕĆÖ’╝īĶó½ĶĄŗõ║łÕĮōÕēŹńÜ䵌ČķŚ┤’╝īÕĘ▓ÕÅ¢ÕŠŚõĖĆõĖ¬Õö»õĖĆÕĆ╝ŃĆé
- ÕģČÕĆ╝µö╣ÕÅśÕ£©IndexWriter.commit->IndexWriter.startCommit->SegmentInfos.prepareCommit->SegmentInfos.write->writeLong(++version)
- ÕģČÕłØÕ¦ŗÕĆ╝õ╣ŗµēƵ£ĆÕłØÕÅ¢õĖĆõĖ¬µŚČķŚ┤’╝īµś»ÕøĀõĖ║µłæõ╗¼Õ╣ČõĖŹÕģ│Õ┐āIndexWriterÕ░åõ┐«µö╣µÅÉõ║żÕł░ń┤óÕ╝ĢńÜäÕģĘõĮōµ¼ĪµĢ░’╝īĶĆīµø┤Õģ│Õ┐āÕł░Õ║ĢÕō¬õĖ¬µś»µ£Ćµ¢░ńÜäŃĆéIndexReaderõĖŁÕĖĖµ»öĶŠāĶć¬ÕĘ▒ńÜäversionÕÆīń┤óÕ╝Ģµ¢ćõ╗ČõĖŁńÜäversionµś»ÕÉ”ńøĖÕÉīµØźÕłżµ¢ŁµŁżIndexReaderĶó½µēōÕ╝ĆÕÉÄ’╝īĶ┐śµ£ēµ▓Īµ£ēĶó½IndexWriterµø┤µ¢░ŃĆé
|
┬Ā //Õ£©DirectoryReaderõĖŁµ£ēõĖĆõĖŗÕćĮµĢ░ŃĆé public boolean isCurrent() throws CorruptIndexException, IOException { ┬Ā return SegmentInfos.readCurrentVersion(directory) == segmentInfos.getVersion(); } |
- NameCount
- µś»õĖŗõĖĆõĖ¬µ¢░µ«Ą(Segment)ńÜ䵫ĄÕÉŹŃĆé
- µēƵ£ēÕ▒×õ║ÄÕÉīõĖĆõĖ¬µ«ĄńÜäń┤óÕ╝Ģµ¢ćõ╗ČķāĮõ╗źµ«ĄÕÉŹõĮ£õĖ║µ¢ćõ╗ČÕÉŹ’╝īõĖĆĶł¼õĖ║_0.xxx, _0.yyy,┬Ā _1.xxx, _1.yyy ŌĆ”ŌĆ”
- µ¢░ńö¤µłÉńÜ䵫ĄńÜ䵫ĄÕÉŹõĖĆĶł¼õĖ║ÕĤµ£ēµ£ĆÕż¦µ«ĄÕÉŹÕŖĀõĖĆŃĆé
- Õ”éÕÉīńÜäń┤óÕ╝Ģ’╝īNameCountĶ»╗Õć║µØźµś»2’╝īĶ»┤µśÄµ¢░ńÜ䵫ĄõĖ║_2.xxx, _2.yyy
┬Ā

- SegCount
- µ«Ą(Segment)ńÜäõĖ¬µĢ░ŃĆé
- Õ”éõĖŖÕøŠ’╝īµŁżÕĆ╝õĖ║2ŃĆé
- SegCountõĖ¬µ«ĄńÜäÕģāµĢ░µŹ«õ┐Īµü»’╝Ü
- SegName
- µ«ĄÕÉŹ’╝īµēƵ£ēÕ▒×õ║ÄÕÉīõĖĆõĖ¬µ«ĄńÜäµ¢ćõ╗ČķāĮµ£ēõ╗źµ«ĄÕÉŹõĮ£õĖ║µ¢ćõ╗ČÕÉŹŃĆé
- Õ”éõĖŖÕøŠ’╝īń¼¼õĖĆõĖ¬µ«ĄńÜ䵫ĄÕÉŹõĖ║"_0"’╝īń¼¼õ║īõĖ¬µ«ĄńÜ䵫ĄÕÉŹõĖ║"_1"
- SegSize
- µŁżµ«ĄõĖŁÕīģÕɽńÜäµ¢ćµĪŻµĢ░
- ńäČĶĆīµŁżµ¢ćµĪŻµĢ░µś»Õīģµŗ¼ÕĘ▓ń╗ÅÕłĀķÖż’╝īÕÅłµ▓Īµ£ēoptimizeńÜäµ¢ćµĪŻńÜä’╝īÕøĀõĖ║Õ£©optimizeõ╣ŗÕēŹ’╝īLuceneńÜ䵫ĄõĖŁÕīģÕɽõ║åµēƵ£ēĶó½ń┤óÕ╝ĢĶ┐ćńÜäµ¢ćµĪŻ’╝īĶĆīĶó½ÕłĀķÖżńÜäµ¢ćµĪŻµś»õ┐ØÕŁśÕ£©.delµ¢ćõ╗ČõĖŁńÜä’╝īÕ£©µÉ£ń┤óńÜäĶ┐ćń©ŗõĖŁ’╝īµś»Õģłõ╗ĵ«ĄõĖŁĶ»╗Õł░õ║åĶó½ÕłĀķÖżńÜäµ¢ćµĪŻ’╝īńäČÕÉÄÕåŹńö©.delõĖŁńÜäµĀćÕ┐Ś’╝īÕ░åĶ┐Öń»ćµ¢ćµĪŻĶ┐ćµ╗żµÄēŃĆé
- Õ”éõĖŗńÜäõ╗ŻńĀüÕĮóµłÉõ║åõĖŖÕøŠńÜäń┤óÕ╝Ģ’╝īÕÅ»õ╗źń£ŗÕć║ń┤óÕ╝Ģõ║åõĖżń»ćµ¢ćµĪŻÕĮóµłÉõ║å_0µ«Ą’╝īńäČÕÉÄÕÅłÕłĀķÖżõ║åÕģČõĖŁõĖĆń»ć’╝īÕĮóµłÉõ║å_0_1.del’╝īÕÅłń┤óÕ╝Ģõ║åõĖżń»ćµ¢ćµĪŻÕĮóµłÉ_1µ«Ą’╝īńäČÕÉÄÕÅłÕłĀķÖżõ║åÕģČõĖŁõĖĆń»ć’╝īÕĮóµłÉ_1_1.delŃĆéÕøĀĶĆīÕ£©õĖżõĖ¬µ«ĄõĖŁ’╝īµŁżÕĆ╝ķāĮµś»2ŃĆé
- SegName
|
┬Ā IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); indexDocs(writer, docDir);//docDirõĖŁÕŬµ£ēõĖżń»ćµ¢ćµĪŻ //µ¢ćµĪŻõĖĆõĖ║’╝ÜStudents should be allowed to go out with their friends, but not allowed to drink beer. //µ¢ćµĪŻõ║īõĖ║’╝ÜMy friend Jerry went to school to see his students but found them drunk which is not allowed. writer.commit();//µÅÉõ║żõĖżń»ćµ¢ćµĪŻ’╝īÕĮóµłÉ_0µ«ĄŃĆé writer.deleteDocuments(new Term("contents", "school"));//ÕłĀķÖżµ¢ćµĪŻõ║ī writer.commit();//µÅÉõ║żÕłĀķÖż’╝īÕĮóµłÉ_0_1.del indexDocs(writer, docDir);//ÕåŹµ¼Īń┤óÕ╝ĢõĖżń»ćµ¢ćµĪŻ’╝īLuceneõĖŹĶāĮÕłżÕł½µ¢ćµĪŻõĖĵ¢ćµĪŻńÜäõĖŹÕÉī’╝īÕøĀĶĆīń«ŚõĖżń»ćµ¢░ńÜäµ¢ćµĪŻŃĆé writer.commit();//µÅÉõ║żõĖżń»ćµ¢ćµĪŻ’╝īÕĮóµłÉ_1µ«Ą writer.deleteDocuments(new Term("contents", "school"));//ÕłĀķÖżń¼¼õ║īµ¼ĪµĘ╗ÕŖĀńÜäµ¢ćµĪŻõ║ī writer.close();//µÅÉõ║żÕłĀķÖż’╝īÕĮóµłÉ_1_1.del |
- ┬Ā
- DelGen
- .delµ¢ćõ╗ČńÜäńēłµ£¼ÕÅĘ
- LuceneõĖŁ’╝īÕ£©optimizeõ╣ŗÕēŹ’╝īÕłĀķÖżńÜäµ¢ćµĪŻµś»õ┐ØÕŁśÕ£©.delµ¢ćõ╗ČõĖŁńÜäŃĆé
- Õ£©Lucene 2.9õĖŁ’╝īµ¢ćµĪŻÕłĀķÖżµ£ēõ╗źõĖŗÕćĀń¦Źµ¢╣Õ╝Å’╝Ü
- IndexReader.deleteDocument(int docID)µś»ńö©IndexReaderµīēµ¢ćµĪŻÕÅĘÕłĀķÖżŃĆé
- IndexReader.deleteDocuments(Term term)µś»ńö©IndexReaderÕłĀķÖżÕīģÕɽµŁżĶ»Ź(Term)ńÜäµ¢ćµĪŻŃĆé
- IndexWriter.deleteDocuments(Term term)µś»ńö©IndexWriterÕłĀķÖżÕīģÕɽµŁżĶ»Ź(Term)ńÜäµ¢ćµĪŻŃĆé
- IndexWriter.deleteDocuments(Term[] terms)µś»ńö©IndexWriterÕłĀķÖżÕīģÕɽĶ┐Öõ║øĶ»Ź(Term)ńÜäµ¢ćµĪŻŃĆé
- IndexWriter.deleteDocuments(Query query)µś»ńö©IndexWriterÕłĀķÖżĶāĮµ╗ĪĶČ│µŁżµ¤źĶ»ó(Query)ńÜäµ¢ćµĪŻŃĆé
- IndexWriter.deleteDocuments(Query[] queries)µś»ńö©IndexWriterÕłĀķÖżĶāĮµ╗ĪĶČ│Ķ┐Öõ║øµ¤źĶ»ó(Query)ńÜäµ¢ćµĪŻŃĆé
- ÕĤµØźńÜäńēłµ£¼õĖŁLuceneńÜäÕłĀķÖżõĖĆńø┤µś»ńö▒IndexReaderµØźÕ«īµłÉńÜä’╝īÕ£©Lucene 2.9õĖŁĶÖĮÕÅ»õ╗źńö©IndexWriterµØźÕłĀķÖż’╝īõĮåµś»ÕģČÕ«×ń£¤µŁŻńÜäÕ«×ńÄ░µś»Õ£©IndexWriterõĖŁ’╝īõ┐ØÕŁśõ║åreaderpool’╝īÕĮōIndexWriterÕÉæń┤óÕ╝Ģµ¢ćõ╗ȵÅÉõ║żÕłĀķÖżńÜ䵌ČÕĆÖ’╝īõ╗Źńäȵś»õ╗ÄreaderpoolõĖŁÕŠŚÕł░ńøĖÕ║öńÜäIndexReader’╝īÕ╣Čńö©IndexReaderµØźĶ┐øĶĪīÕłĀķÖżńÜäŃĆéõĖŗķØóńÜäõ╗ŻńĀüÕÅ»õ╗źĶ»┤µśÄ’╝Ü
- DelGen
|
┬Ā IndexWriter.applyDeletes() -> DocumentsWriter.applyDeletes(SegmentInfos) ┬Ā┬Ā┬Ā┬Ā -> reader.deleteDocument(doc); |
- ┬Ā
- ┬Ā
- ┬Ā
- DelGenµś»µ»ÅÕĮōIndexWriterÕÉæń┤óÕ╝Ģµ¢ćõ╗ČõĖŁµÅÉõ║żÕłĀķÖżµōŹõĮ£ńÜ䵌ČÕĆÖ’╝īÕŖĀ1’╝īÕ╣Čńö¤µłÉµ¢░ńÜä.delµ¢ćõ╗ČŃĆé
- ┬Ā
- ┬Ā
|
┬Ā IndexWriter.commit() -> IndexWriter.applyDeletes() ┬Ā┬Ā┬Ā -> IndexWriter$ReaderPool.release(SegmentReader) ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā -> SegmentReader(IndexReader).commit() ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā -> SegmentReader.doCommit(Map) ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā -> SegmentInfo.advanceDelGen() ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā -> if (delGen == NO) { ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā delGen = YES; ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā } else { ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā delGen++; ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā } |
|
┬Ā IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); writer.setUseCompoundFile(false); indexDocs(writer, docDir);//ń┤óÕ╝ĢõĖżń»ćµ¢ćµĪŻ’╝īõĖĆń»ćÕīģÕɽ"school"’╝īÕÅ”õĖĆń»ćÕīģÕɽ"beer" writer.commit();//µÅÉõ║żõĖżń»ćµ¢ćµĪŻÕł░ń┤óÕ╝Ģµ¢ćõ╗Č’╝īÕĮóµłÉµ«Ą(Segment) "_0" writer.deleteDocuments(new Term("contents", "school"));//ÕłĀķÖżÕīģÕɽ"school"ńÜäµ¢ćµĪŻ’╝īÕģČÕ«×µś»ÕłĀķÖżõ║åõĖżń»ćµ¢ćµĪŻõĖŁńÜäõĖĆń»ćŃĆé writer.commit();//µÅÉõ║żÕłĀķÖżÕł░ń┤óÕ╝Ģµ¢ćõ╗Č’╝īÕĮóµłÉ"_0_1.del" writer.deleteDocuments(new Term("contents", "beer"));//ÕłĀķÖżÕīģÕɽ"beer"ńÜäµ¢ćµĪŻ’╝īÕģČÕ«×µś»ÕłĀķÖżõ║åõĖżń»ćµ¢ćµĪŻõĖŁńÜäÕÅ”õĖĆń»ćŃĆé writer.commit();//µÅÉõ║żÕłĀķÖżÕł░ń┤óÕ╝Ģµ¢ćõ╗Č’╝īÕĮóµłÉ"_0_2.del" indexDocs(writer, docDir);//ń┤óÕ╝ĢõĖżń»ćµ¢ćµĪŻ’╝īÕÆīõĖŖµ¼ĪńÜäµ¢ćµĪŻńøĖÕÉī’╝īõĮåµś»LuceneµŚĀµ│ĢÕī║Õłå’╝īĶ«żõĖ║µś»ÕÅ”Õż¢õĖżń»ćµ¢ćµĪŻŃĆé writer.commit();//µÅÉõ║żõĖżń»ćµ¢ćµĪŻÕł░ń┤óÕ╝Ģµ¢ćõ╗Č’╝īÕĮóµłÉµ«Ą"_1" writer.deleteDocuments(new Term("contents", "beer"));//ÕłĀķÖżÕīģÕɽ"beer"ńÜäµ¢ćµĪŻ’╝īÕģČõĖŁµ«Ą"_0"ÕĘ▓ń╗ŵŚĀÕÅ»ÕłĀķÖż’╝īµ«Ą"_1"Ķó½ÕłĀķÖżõĖĆń»ćŃĆé writer.close();//µÅÉõ║żÕłĀķÖżÕł░ń┤óÕ╝Ģµ¢ćõ╗Č’╝īÕĮóµłÉ"_1_1.del" ÕĮóµłÉńÜäń┤óÕ╝Ģµ¢ćõ╗ČÕ”éõĖŗ’╝Ü
|

┬Ā
┬Ā
- ┬Ā
- DocStoreOffset
- DocStoreSegment
- DocStoreIsCompoundFile
- Õ»╣õ║ÄÕ¤¤(Stored Field)ÕÆīĶ»ŹÕÉæķćÅ(Term Vector)ńÜäÕŁśÕé©ÕÅ»õ╗źµ£ēõĖŹÕÉīńÜäµ¢╣Õ╝Å’╝īÕŹ│ÕÅ»õ╗źµ»ÅõĖ¬µ«Ą(Segment)ÕŹĢńŗ¼ÕŁśÕé©Ķć¬ÕĘ▒ńÜäÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»’╝īõ╣¤ÕÅ»õ╗źÕżÜõĖ¬µ«ĄÕģ▒õ║½Õ¤¤ÕÆīĶ»ŹÕÉæķćÅ’╝īµŖŖÕ«āõ╗¼ÕŁśÕé©Õł░õĖĆõĖ¬µ«ĄõĖŁÕÄ╗ŃĆé
- Õ”éµ×£DocStoreOffsetõĖ║-1’╝īÕłÖµŁżµ«ĄÕŹĢńŗ¼ÕŁśÕé©Ķć¬ÕĘ▒ńÜäÕ¤¤ÕÆīĶ»ŹÕÉæķćÅ’╝īõ╗ÄÕŁśÕ驵¢ćõ╗ČõĖŖµØźń£ŗ’╝īÕ”éµ×£µŁżµ«Ąµ«ĄÕÉŹõĖ║XXX’╝īÕłÖµŁżµ«Ąµ£ēĶć¬ÕĘ▒ńÜäXXX.fdt’╝īXXX.fdx’╝īXXX.tvf’╝īXXX.tvd’╝īXXX.tvxµ¢ćõ╗ČŃĆéDocStoreSegmentÕÆīDocStoreIsCompoundFileÕ£©µŁżÕżäõĖŹĶó½õ┐ØÕŁśŃĆé
- Õ”éµ×£DocStoreOffsetõĖŹõĖ║-1’╝īÕłÖDocStoreSegmentõ┐ØÕŁśõ║åÕģ▒õ║½ńÜ䵫ĄńÜäÕÉŹÕŁŚ’╝īµ»öÕ”éõĖ║YYY’╝īDocStoreOffsetÕłÖõĖ║µŁżµ«ĄńÜäÕ¤¤ÕÅŖĶ»ŹÕÉæķćÅõ┐Īµü»Õ£©Õģ▒õ║½µ«ĄõĖŁńÜäÕüÅń¦╗ķćÅŃĆéÕłÖµŁżµ«Ąµ▓Īµ£ēĶć¬ÕĘ▒ńÜäXXX.fdt’╝īXXX.fdx’╝īXXX.tvf’╝īXXX.tvd’╝īXXX.tvxµ¢ćõ╗Č’╝īĶĆīµś»Õ░åõ┐Īµü»ÕŁśµöŠÕ£©Õģ▒õ║½µ«ĄńÜäYYY.fdt’╝īYYY.fdx’╝īYYY.tvf’╝īYYY.tvd’╝īYYY.tvxµ¢ćõ╗ČõĖŁŃĆé
- DocumentsWriterõĖŁµ£ēõĖżõĖ¬µłÉÕæśÕÅśķćÅ’╝ÜString segmentµś»ÕĮōÕēŹń┤óÕ╝Ģõ┐Īµü»ÕŁśµöŠńÜ䵫Ą’╝īString docStoreSegmentµś»Õ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»ÕŁśÕé©ńÜ䵫ĄŃĆéõĖżĶĆģÕÅ»õ╗źńøĖÕÉīõ╣¤ÕÅ»õ╗źõĖŹÕÉī’╝īÕå│Õ«Üõ║åÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»µś»ÕŁśÕé©Õ£©µ£¼µ«ĄõĖŁ’╝īĶ┐śµś»ÕÆīÕģČõ╗¢ńÜ䵫ĄÕģ▒õ║½ŃĆé
- IndexWriter.flush(boolean triggerMerge, boolean flushDocStores, boolean flushDeletes)õĖŁń¼¼õ║īõĖ¬ÕÅéµĢ░flushDocStoresõ╝ÜÕĮ▒ÕōŹÕł░µś»ÕÉ”ÕŹĢńŗ¼µł¢µś»Õģ▒õ║½ÕŁśÕé©ŃĆéÕģČÕ«×µ£Ćń╗łÕĮ▒ÕōŹńÜ䵜»DocumentsWriter.closeDocStore()ŃĆéµ»ÅÕĮōflushDocStoresõĖ║falseµŚČ’╝īcloseDocStoreõĖŹĶó½Ķ░āńö©’╝īĶ»┤µśÄõĖŗµ¼ĪµĘ╗ÕŖĀÕł░ń┤óÕ╝Ģµ¢ćõ╗ČõĖŁńÜäÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»µś»ÕÉīµŁżµ¼ĪÕģ▒õ║½õĖĆõĖ¬µ«ĄńÜäŃĆéńø┤Õł░flushDocStoresõĖ║trueńÜ䵌ČÕĆÖ’╝īcloseDocStoreĶó½Ķ░āńö©’╝īõ╗ÄĶĆīõĖŗµ¼ĪµĘ╗ÕŖĀÕł░ń┤óÕ╝Ģµ¢ćõ╗ČõĖŁńÜäÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»Õ░åĶó½õ┐ØÕŁśÕ£©õĖĆõĖ¬µ¢░ńÜ䵫ĄõĖŁ’╝īõĖŹÕÉīµŁżµ¼ĪÕģ▒õ║½õĖĆõĖ¬µ«Ą(Õ£©Ķ┐Öķćīķ£ĆĶ”üµīćÕć║ńÜ䵜»LuceneńÜäõĖĆõĖ¬ÕŠłÕźćµĆ¬ńÜäÕ«×ńÄ░’╝īĶÖĮńäČõĖŗµ¼ĪÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»µś»Ķó½õ┐ØÕŁśÕł░µ¢░ńÜ䵫ĄõĖŁ’╝īńäČĶĆīµ«ĄÕÉŹÕŹ┤µś»Ķ┐Öµ¼ĪĶó½ńĪ«Õ«Üõ║åńÜä’╝īÕ£©initSegmentNameõĖŁÕĮōdocStoreSegment == nullµŚČ’╝īĶó½ńĮ«õĖ║ÕĮōÕēŹńÜäsegment’╝īĶĆīķØ×õĖŗõĖĆõĖ¬µ¢░ńÜäsegment’╝īdocStoreSegment = segment’╝īõ║ĵś»õ╝ÜÕć║ńÄ░Õ”éõĖŗķØóńÜäõŠŗÕŁÉńÜäńÄ░Ķ▒Ī)ŃĆé
- ÕźĮÕ£©Õģ▒õ║½Õ¤¤ÕÆīĶ»ŹÕÉæķćÅÕŁśÕé©Õ╣ČõĖŹµś»ń╗ÅÕĖĖĶó½õĮ┐ńö©Õł░’╝īÕ«×ńÄ░õ╣¤µł¢µ£ēń╝║ķÖĘ’╝īµÜéõĖöĶ¦ŻķćŖÕł░µŁżŃĆé
|
┬Ā ┬Ā┬Ā┬Ā┬Ā┬Ā IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.setUseCompoundFile(false); ┬Ā ┬Ā┬Ā┬Ā┬Ā┬Ā indexDocs(writer, docDir); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.flush(); //flushńö¤µłÉsegment "_0"’╝īÕ╣ČõĖöflushÕćĮµĢ░õĖŁ’╝īflushDocStoresĶ«ŠõĖ║false’╝īõ╣¤ÕŹ│õĖŗõĖ¬µ«ĄÕ░åÕÉīµ£¼µ«ĄÕģ▒õ║½Õ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»’╝īĶ┐ÖµŚČDocumentsWriterõĖŁńÜädocStoreSegment= "_0"ŃĆé ┬Ā┬Ā┬Ā┬Ā┬Ā indexDocs(writer, docDir); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.commit(); //commitńö¤µłÉsegment "_1"’╝īńö▒õ║ÄõĖŖµ¼ĪflushDocStoresĶ«ŠõĖ║false’╝īõ║ĵś»µ«Ą"_1"ńÜäÕ¤¤õ╗źÕÅŖĶ»ŹÕÉæķćÅõ┐Īµü»µś»õ┐ØÕŁśÕ£©"_0"õĖŁńÜä’╝īÕ£©Ķ┐ÖõĖ¬µŚČÕł╗’╝īµ«Ą"_1"Õ╣ČõĖŹńö¤µłÉĶć¬ÕĘ▒ńÜä"_1.fdx"ÕÆī"_1.fdt"ŃĆéńäČĶĆīÕ£©commitÕćĮµĢ░õĖŁ’╝īflushDocStoresĶ«ŠõĖ║true’╝īõ╣¤ÕŹ│õĖŗõĖ¬µ«ĄÕ░åÕŹĢńŗ¼õĮ┐ńö©µ¢░ńÜ䵫ĄµØźÕŁśÕé©Õ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»ŃĆéńäČĶĆīĶ┐ÖµŚČ’╝īDocumentsWriterõĖŁńÜädocStoreSegment= "_1"’╝īõ╣¤ÕŹ│ÕĮōµ«Ą"_2"ÕŁśÕé©ÕģČÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»ńÜ䵌ČÕĆÖ’╝īµś»ÕŁśÕ£©"_1.fdx"ÕÆī"_1.fdt"õĖŁńÜä’╝īĶĆīµ«Ą"_1"ńÜäÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»ÕŹ┤µś»ÕŁśÕ£©"_0.fdt"ÕÆī"_0.fdx"õĖŁńÜä’╝īĶ┐ÖõĖĆńé╣ķØ×ÕĖĖõ╗żõ║║Õø░µāæŃĆé Õ”éÕøŠwriter.commitńÜ䵌ČÕĆÖ’╝ī_1.fdtÕÆī_1.fdxÕ╣ȵ▓Īµ£ēÕĮóµłÉŃĆé
┬Ā┬Ā┬Ā┬Ā┬Ā indexDocs(writer, docDir); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.flush(); //µ«Ą"_2"ÕĮóµłÉ’╝īńö▒õ║ÄõĖŖµ¼ĪflushDocStoresĶ«ŠõĖ║true’╝īÕģČÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»µś»µ¢░ÕłøÕ╗║õĖĆõĖ¬µ«Ąõ┐ØÕŁśńÜä’╝īÕŹ┤µś»õ┐ØÕŁśÕ£©_1.fdtÕÆī_1.fdxõĖŁńÜä’╝īĶ┐ÖµŚČÕĆÖµēŹõ║¦ńö¤õ║åµŁżõ║īµ¢ćõ╗ČŃĆé
┬Ā┬Ā┬Ā┬Ā┬Ā indexDocs(writer, docDir); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.flush(); //µ«Ą"_3"ÕĮóµłÉ’╝īńö▒õ║ÄõĖŖµ¼ĪflushDocStoresĶ«ŠõĖ║false’╝īÕģČÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»µś»Õģ▒õ║½õĖĆõĖ¬µ«Ąõ┐ØÕŁśńÜä’╝īõ╣¤µś»µś»õ┐ØÕŁśÕ£©_1.fdtÕÆī_1.fdxõĖŁńÜä ┬Ā┬Ā┬Ā┬Ā┬Ā indexDocs(writer, docDir); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.commit(); //µ«Ą"_4"ÕĮóµłÉ’╝īńö▒õ║ÄõĖŖµ¼ĪflushDocStoresĶ«ŠõĖ║false’╝īÕģČÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»µś»Õģ▒õ║½õĖĆõĖ¬µ«Ąõ┐ØÕŁśńÜä’╝īõ╣¤µś»µś»õ┐ØÕŁśÕ£©_1.fdtÕÆī_1.fdxõĖŁńÜäŃĆéńäČĶĆīÕćĮµĢ░commitõĖŁflushDocStoresĶ«ŠõĖ║true’╝īõ╣¤µäÅÕæ│ńØĆõĖŗõĖĆõĖ¬µ«ĄÕ░åµ¢░ÕłøÕ╗║õĖĆõĖ¬µ«Ąõ┐ØÕŁśÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»’╝īµŁżµŚČDocumentsWriterõĖŁdocStoreSegment= "_4"’╝īõ╣¤ĶĪ©µśÄõ║åĶÖĮńäȵ«Ą"_4"ńÜäÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»õ┐ØÕŁśÕ£©õ║嵫Ą"_1"õĖŁ’╝īÕ░åµØźńÜäÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»ÕŹ┤Ķ”üõ┐ØÕŁśÕ£©µ«Ą"_4"õĖŁŃĆ鵣żµŚČ"_4.fdx"ÕÆī"_4.fdt"Õ░ܵ£¬õ║¦ńö¤ŃĆé┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā indexDocs(writer, docDir); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.flush(); //µ«Ą"_5"ÕĮóµłÉ’╝īńö▒õ║ÄõĖŖµ¼ĪflushDocStoresĶ«ŠõĖ║true’╝īÕģČÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»µś»µ¢░ÕłøÕ╗║õĖĆõĖ¬µ«Ąõ┐ØÕŁśńÜä’╝īÕŹ┤µś»õ┐ØÕŁśÕ£©_4.fdtÕÆī_4.fdxõĖŁńÜä’╝īĶ┐ÖµŚČÕĆÖµēŹõ║¦ńö¤õ║åµŁżõ║īµ¢ćõ╗ČŃĆé
┬Ā┬Ā┬Ā┬Ā┬Ā indexDocs(writer, docDir); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.commit(); ┬Ā┬Ā┬Ā┬Ā┬Ā writer.close(); //µ«Ą"_6"ÕĮóµłÉ’╝īńö▒õ║ÄõĖŖµ¼ĪflushDocStoresĶ«ŠõĖ║false’╝īÕģČÕ¤¤ÕÆīĶ»ŹÕÉæķćÅõ┐Īµü»µś»Õģ▒õ║½õĖĆõĖ¬µ«Ąõ┐ØÕŁśńÜä’╝īõ╣¤µś»µś»õ┐ØÕŁśÕ£©_4.fdtÕÆī_4.fdxõĖŁńÜä
|





- ┬Ā
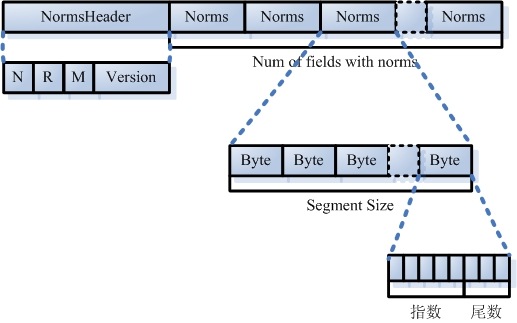
- HasSingleNormFile
- Õ£©µÉ£ń┤óńÜäĶ┐ćń©ŗõĖŁ’╝īµĀćÕćåÕī¢ÕøĀÕŁÉ(Normalization Factor)õ╝ÜÕĮ▒ÕōŹµ¢ćµĪŻµ£ĆÕÉÄńÜäĶ»äÕłåŃĆé
- õĖŹÕÉīńÜäµ¢ćµĪŻķćŹĶ”üµĆ¦õĖŹÕÉī’╝īõĖŹÕÉīńÜäÕ¤¤ķćŹĶ”üµĆ¦õ╣¤õĖŹÕÉīŃĆéÕøĀĶĆīµ»ÅõĖ¬µ¢ćµĪŻńÜäµ»ÅõĖ¬Õ¤¤ķāĮÕÅ»õ╗źµ£ēĶć¬ÕĘ▒ńÜäµĀćÕćåÕī¢ÕøĀÕŁÉŃĆé
- Õ”éµ×£HasSingleNormFileõĖ║1’╝īÕłÖµēƵ£ēńÜäµĀćÕćåÕī¢ÕøĀÕŁÉķāĮµś»ÕŁśÕ£©.nrmµ¢ćõ╗ČõĖŁńÜäŃĆé
- Õ”éµ×£HasSingleNormFileõĖŹµś»1’╝īÕłÖµ»ÅõĖ¬Õ¤¤ķāĮµ£ēĶć¬ÕĘ▒ńÜäµĀćÕćåÕī¢ÕøĀÕŁÉµ¢ćõ╗Č.fN
- NumField
- Õ¤¤ńÜäµĢ░ķćÅ
- NormGen
- Õ”éµ×£µ»ÅõĖ¬Õ¤¤µ£ēĶć¬ÕĘ▒ńÜäµĀćÕćåÕī¢ÕøĀÕŁÉµ¢ćõ╗Č’╝īÕłÖµŁżµĢ░ń╗äµÅÅĶ┐░õ║åµ»ÅõĖ¬µĀćÕćåÕī¢ÕøĀÕŁÉµ¢ćõ╗ČńÜäńēłµ£¼ÕÅĘ’╝īõ╣¤ÕŹ│.fNńÜäNŃĆé
- IsCompoundFile
- µś»ÕÉ”õ┐ØÕŁśõĖ║ÕżŹÕÉłµ¢ćõ╗Č’╝īõ╣¤ÕŹ│µŖŖÕÉīõĖĆõĖ¬µ«ĄõĖŁńÜäµ¢ćõ╗ȵīēńģ¦õĖĆիܵĀ╝Õ╝Å’╝īõ┐ØÕŁśÕ£©õĖĆõĖ¬µ¢ćõ╗ČÕĮōõĖŁ’╝īĶ┐ÖµĀĘÕÅ»õ╗źÕćÅÕ░浻ŵ¼ĪµēōÕ╝Ƶ¢ćõ╗ČńÜäõĖ¬µĢ░ŃĆé
- µś»ÕÉ”õĖ║ÕżŹÕÉłµ¢ćõ╗Č’╝īńö▒µÄźÕÅŻIndexWriter.setUseCompoundFile(boolean)Ķ«ŠÕ«ÜŃĆé┬Ā
- ķØ×ń¼”ÕÉłµ¢ćõ╗ČÕÉīń¼”ÕÉłµ¢ćõ╗ČńÜäÕ»╣µ»öÕ”éõĖŗÕøŠ’╝Ü
- HasSingleNormFile
| ķØ×ÕżŹÕÉłµ¢ćõ╗Č’╝Ü
┬Ā
|
ÕżŹÕÉłµ¢ćõ╗Č’╝Ü
┬Ā
|


┬Ā
┬Ā
- ┬Ā
- DeletionCount
- Ķ«░ÕĮĢõ║åµŁżµ«ĄõĖŁÕłĀķÖżńÜäµ¢ćµĪŻńÜäµĢ░ńø«ŃĆé
- HasProx
- Õ”éµ×£Ķć│Õ░æµ£ēõĖĆõĖ¬µ«ĄomitTfõĖ║false’╝īõ╣¤ÕŹ│Ķ»Źķóæ(term freqency)ķ£ĆĶ”üĶó½õ┐ØÕŁś’╝īÕłÖHasProxõĖ║1’╝īÕÉ”ÕłÖõĖ║0ŃĆé
- Diagnostics
- Ķ░āĶ»Ģõ┐Īµü»ŃĆé
- DeletionCount
- User map data
- õ┐ØÕŁśõ║åńö©µłĘõ╗ÄÕŁŚń¼”õĖ▓Õł░ÕŁŚń¼”õĖ▓ńÜ䵜ĀÕ░äMap
- CheckSum
- µŁżµ¢ćõ╗Čsegment_NńÜäµĀĪķ¬īÕÆīŃĆé
|
┬Ā Ķ»╗ÕÅ¢µŁżµ¢ćõ╗ȵĀ╝Õ╝ÅÕÅéĶĆāSegmentInfos.read(Directory directory, String segmentFileName):
|
┬Ā
┬Ā
4.1.2. Õ¤¤(Field)ńÜäÕģāµĢ░µŹ«õ┐Īµü»(.fnm)
õĖĆõĖ¬µ«Ą(Segment)ÕīģÕÉ½ÕżÜõĖ¬Õ¤¤’╝īµ»ÅõĖ¬Õ¤¤ķāĮµ£ēõĖĆõ║øÕģāµĢ░µŹ«õ┐Īµü»’╝īõ┐ØÕŁśÕ£©.fnmµ¢ćõ╗ČõĖŁ’╝ī.fnmµ¢ćõ╗ČńÜäµĀ╝Õ╝ÅÕ”éõĖŗ’╝Ü

- FNMVersion
- µś»fnmµ¢ćõ╗ČńÜäńēłµ£¼ÕÅĘ’╝īÕ»╣õ║ÄLucene 2.9õĖ║-2
- FieldsCount
- Õ¤¤ńÜäµĢ░ńø«
- õĖĆõĖ¬µĢ░ń╗äńÜäÕ¤¤(Fields)
- FieldName’╝ÜÕ¤¤ÕÉŹ’╝īÕ”é"title"’╝ī"modified"’╝ī"content"ńŁēŃĆé
- FieldBits:õĖĆń│╗ÕłŚµĀćÕ┐ŚõĮŹ’╝īĶĪ©µśÄÕ»╣µŁżÕ¤¤ńÜäń┤óÕ╝Ģµ¢╣Õ╝Å
- µ£ĆõĮÄõĮŹ’╝Ü1ĶĪ©ńż║µŁżÕ¤¤Ķó½ń┤óÕ╝Ģ’╝ī0ÕłÖõĖŹĶó½ń┤óÕ╝ĢŃĆéµēĆĶ░ōĶó½ń┤óÕ╝Ģ’╝īõ╣¤ÕŹ│µöŠÕł░ÕĆƵÄÆĶĪ©õĖŁÕÄ╗ŃĆé
- õ╗ģõ╗ģĶó½ń┤óÕ╝ĢńÜäÕ¤¤µēŹĶāĮÕż¤Ķó½µÉ£Õł░ŃĆé
- Field.Index.NOÕłÖĶĪ©ńż║õĖŹĶó½ń┤óÕ╝ĢŃĆé
- Field.Index.ANALYZEDÕłÖĶĪ©ńż║õĖŹõĮåĶó½ń┤óÕ╝Ģ’╝īĶĆīõĖöĶó½ÕłåĶ»Ź’╝īµ»öÕ”éń┤óÕ╝Ģ"hello world"ÕÉÄ’╝īµŚĀĶ«║µś»µÉ£"hello"’╝īĶ┐śµś»µÉ£"world"ķāĮĶāĮÕż¤Ķó½µÉ£Õł░ŃĆé
- Field.Index.NOT_ANALYZEDĶĪ©ńż║ĶÖĮńäČĶó½ń┤óÕ╝Ģ’╝īõĮåµś»õĖŹÕłåĶ»Ź’╝īµ»öÕ”éń┤óÕ╝Ģ"hello world"ÕÉÄ’╝īõ╗ģÕĮōµÉ£"hello world"µŚČ’╝īĶāĮÕż¤µÉ£Õł░’╝īµÉ£"hello"ÕÆīµÉ£"world"ķāĮµÉ£õĖŹÕł░ŃĆé
- õĖĆõĖ¬Õ¤¤Õć║õ║åĶāĮÕż¤Ķó½ń┤óÕ╝Ģ’╝īĶ┐śĶāĮÕż¤Ķó½ÕŁśÕé©’╝īõ╗ģõ╗ģĶó½ÕŁśÕé©ńÜäÕ¤¤µś»µÉ£ń┤óõĖŹÕł░ńÜä’╝īõĮåµś»ĶāĮķĆÜĶ┐ćµ¢ćµĪŻÕÅʵ¤źÕł░’╝īÕżÜńö©õ║ÄõĖŹµā│Ķó½µÉ£ń┤óÕł░’╝īõĮåµś»Õ£©ķĆÜĶ┐ćÕģČÕ«āÕ¤¤ĶāĮÕż¤µÉ£ń┤óÕł░ńÜäµāģÕåĄõĖŗ’╝īĶāĮÕż¤ķÜÅńØƵ¢ćµĪŻÕÅĘĶ┐öÕø×ń╗Öńö©µłĘńÜäÕ¤¤ŃĆé
- Field.Store.YesÕłÖĶĪ©ńż║ÕŁśÕ驵ŁżÕ¤¤’╝īField.Store.NOÕłÖĶĪ©ńż║õĖŹÕŁśÕ驵ŁżÕ¤¤ŃĆé
- ÕĆƵĢ░ń¼¼õ║īõĮŹ’╝Ü1ĶĪ©ńż║õ┐ØÕŁśĶ»ŹÕÉæķćÅ’╝ī0õĖ║õĖŹõ┐ØÕŁśĶ»ŹÕÉæķćÅŃĆé
- Field.TermVector.YESĶĪ©ńż║õ┐ØÕŁśĶ»ŹÕÉæķćÅŃĆé
- Field.TermVector.NOĶĪ©ńż║õĖŹõ┐ØÕŁśĶ»ŹÕÉæķćÅŃĆé
- ÕĆƵĢ░ń¼¼õĖēõĮŹ’╝Ü1ĶĪ©ńż║Õ£©Ķ»ŹÕÉæķćÅõĖŁõ┐ØÕŁśõĮŹńĮ«õ┐Īµü»ŃĆé
- Field.TermVector.WITH_POSITIONS
- ÕĆƵĢ░ń¼¼ÕøøõĮŹ’╝Ü1ĶĪ©ńż║Õ£©Ķ»ŹÕÉæķćÅõĖŁõ┐ØÕŁśÕüÅń¦╗ķćÅõ┐Īµü»ŃĆé
- Field.TermVector.WITH_OFFSETS
- ÕĆƵĢ░ń¼¼õ║öõĮŹ’╝Ü1ĶĪ©ńż║õĖŹõ┐ØÕŁśµĀćÕćåÕī¢ÕøĀÕŁÉ
- Field.Index.ANALYZED_NO_NORMS
- Field.Index.NOT_ANALYZED_NO_NORMS
- ÕĆƵĢ░ń¼¼ÕģŁõĮŹ’╝ܵś»ÕÉ”õ┐ØÕŁśpayload
- µ£ĆõĮÄõĮŹ’╝Ü1ĶĪ©ńż║µŁżÕ¤¤Ķó½ń┤óÕ╝Ģ’╝ī0ÕłÖõĖŹĶó½ń┤óÕ╝ĢŃĆéµēĆĶ░ōĶó½ń┤óÕ╝Ģ’╝īõ╣¤ÕŹ│µöŠÕł░ÕĆƵÄÆĶĪ©õĖŁÕÄ╗ŃĆé
┬Ā
Ķ”üõ║åĶ¦ŻÕ¤¤ńÜäÕģāµĢ░µŹ«õ┐Īµü»’╝īĶ┐śĶ”üõ║åĶ¦Żõ╗źõĖŗÕćĀńé╣’╝Ü
- õĮŹńĮ«(Position)ÕÆīÕüÅń¦╗ķćÅ(Offset)ńÜäÕī║Õł½
- õĮŹńĮ«µś»Õ¤║õ║ÄĶ»ŹTermńÜä’╝īÕüÅń¦╗ķćŵś»Õ¤║õ║ÄÕŁŚµ»Źµł¢µ▒ēÕŁŚńÜäŃĆé
┬Ā

- ń┤óÕ╝ĢÕ¤¤(Indexed)ÕÆīÕŁśÕé©Õ¤¤(Stored)ńÜäÕī║Õł½
- õĖĆõĖ¬Õ¤¤õĖ║õ╗Ćõ╣łõ╝ÜĶó½ÕŁśÕé©(store)ĶĆīõĖŹĶó½ń┤óÕ╝Ģ(Index)Õæó’╝¤Õ£©õĖĆõĖ¬µ¢ćµĪŻõĖŁńÜäµēƵ£ēõ┐Īµü»õĖŁ’╝īµ£ēĶ┐ÖµĀĘõĖĆķā©Õłåõ┐Īµü»’╝īÕÅ»ĶāĮõĖŹµā│Ķó½ń┤óÕ╝Ģõ╗ÄĶĆīÕÅ»õ╗źµÉ£ń┤óÕł░’╝īõĮåµś»ÕĮōĶ┐ÖõĖ¬µ¢ćµĪŻńö▒õ║ÄÕģČõ╗¢ńÜäõ┐Īµü»Ķó½µÉ£ń┤óÕł░µŚČ’╝īÕÅ»õ╗źÕÉīÕģČõ╗¢õ┐Īµü»õĖĆÕÉīĶ┐öÕø×ŃĆé
- õĖŠõĖ¬õŠŗÕŁÉ’╝īĶ»╗ńĀöń®Čńö¤µŚČ’╝īµé©ÕźĮõĖŹÕ«╣µśōÕåÖõ║åõĖĆń»ćĶ«║µ¢ćõ║żń╗Öµé©ńÜäÕ»╝ÕĖł’╝īµé©ńÜäÕ»╝ÕĖłÕŹ┤Ķ”üõ╗¢µēĆń¼¼õĖĆõĮ£ĶĆģĶĆīµé©ÕüÜń¼¼õ║īõĮ£ĶĆģ’╝īńäČĶĆīµé©Õ»╝ÕĖłõĖŹµā│Õł½õ║║Õ£©Ķ«║µ¢ćń│╗ń╗¤õĖŁµÉ£ń┤óµé©ńÜäÕÉŹÕŁŚµŚČµēŠÕł░Ķ┐Öń»ćĶ«║µ¢ć’╝īõ║ĵś»Õ£©Ķ«║µ¢ćń│╗ń╗¤õĖŁ’╝īµŖŖń¼¼õ║īõĮ£ĶĆģĶ┐ÖõĖ¬FieldńÜäIndexedĶ«ŠõĖ║false’╝īĶ┐ÖµĀĘÕł½õ║║µÉ£ń┤óµé©ńÜäÕÉŹÕŁŚ’╝īµ░ĖĶ┐£õĖŹń¤źķüōµé©ÕåÖĶ┐ćĶ┐Öń»ćĶ«║µ¢ć’╝īÕŬµ£ēÕ£©Õł½õ║║µÉ£ń┤óµé©Õ»╝ÕĖłńÜäÕÉŹÕŁŚõ╗ÄĶĆīµēŠÕł░µé©ńÜäµ¢ćń½ĀµŚČ’╝īÕ£©õĖĆõĖ¬Ķ¦ÆĶÉĮĶĪ©Ķ┐░ńØĆń¼¼õ║īõĮ£ĶĆģµś»µé©ŃĆé
- payloadńÜäõĮ┐ńö©
- µłæõ╗¼ń¤źķüō’╝īń┤óÕ╝Ģµś»õ╗źÕĆƵÄÆĶĪ©ÕĮóÕ╝ÅÕŁśÕé©ńÜä’╝īÕ»╣õ║ĵ»ÅõĖĆõĖ¬Ķ»Ź’╝īķāĮõ┐ØÕŁśõ║åÕīģÕɽĶ┐ÖõĖ¬Ķ»ŹńÜäõĖĆõĖ¬ķōŠĶĪ©’╝īÕĮōńäČõĖ║õ║åÕŖĀÕ┐½µ¤źĶ»óķƤÕ║”’╝īµŁżķōŠĶĪ©ÕżÜńö©ĶĘ│ĶĘāĶĪ©Ķ┐øĶĪīÕŁśÕé©ŃĆé
- Payloadõ┐Īµü»Õ░▒µś»ÕŁśÕé©Õ£©ÕĆƵÄÆĶĪ©õĖŁńÜä’╝īÕÉīµ¢ćµĪŻÕÅĘõĖĆĶĄĘÕŁśµöŠ’╝īÕżÜńö©õ║ÄÕŁśÕé©õĖĵ»Åń»ćµ¢ćµĪŻńøĖÕģ│ńÜäõĖĆõ║øõ┐Īµü»ŃĆéÕĮōńäČĶ┐Öķā©Õłåõ┐Īµü»õ╣¤ÕÅ»õ╗źÕŁśÕé©Õ¤¤ķćī(stored Field)’╝īõĖżĶĆģõ╗ÄÕŖ¤ĶāĮõĖŖÕ¤║µ£¼µś»õĖƵĀĘńÜä’╝īńäČĶĆīÕĮōĶ”üÕŁśÕé©ńÜäõ┐Īµü»ÕŠłÕżÜńÜ䵌ČÕĆÖ’╝īÕŁśµöŠÕ£©ÕĆƵÄÆĶĪ©ķćī’╝īÕł®ńö©ĶĘ│ĶĘāĶĪ©’╝īµ£ēÕł®õ║ÄÕż¦Õż¦µÅÉķ½śµÉ£ń┤óķƤÕ║”ŃĆé
- PayloadńÜäÕŁśÕ驵¢╣Õ╝ÅÕ”éõĖŗÕøŠ’╝Ü
┬Ā

- ┬Ā
- PayloadõĖ╗Ķ”üµ£ēõ╗źõĖŗÕćĀń¦Źńö©µ│Ģ’╝Ü
- ÕŁśÕ驵»ÅõĖ¬µ¢ćµĪŻķāĮµ£ēńÜäõ┐Īµü»’╝ܵ»öՔ鵣ēńÜ䵌ČÕĆÖ’╝īµłæõ╗¼µā│ń╗Öµ»ÅõĖ¬µ¢ćµĪŻĶĄŗõĖĆõĖ¬µłæõ╗¼Ķć¬ÕĘ▒ńÜäµ¢ćµĪŻÕÅĘ’╝īĶĆīõĖŹµś»ńö©LuceneĶć¬ÕĘ▒ńÜäµ¢ćµĪŻÕÅĘŃĆéõ║ĵś»µłæõ╗¼ÕÅ»õ╗źÕŻ░µśÄõĖĆõĖ¬ńē╣µ«ŖńÜäÕ¤¤(Field)"_ID"ÕÆīńē╣µ«ŖńÜäĶ»Ź(Term)"_ID"’╝īõĮ┐ÕŠŚµ»Åń»ćµ¢ćµĪŻķāĮÕīģÕɽĶ»Ź"_ID"’╝īõ║ĵś»Õ£©Ķ»Ź"_ID"ńÜäÕĆƵÄÆĶĪ©ķćīķØóÕ»╣õ║ĵ»Åń»ćµ¢ćµĪŻÕÅłµ£ēõĖĆķĪ╣’╝īµ»ÅõĖĆķĪ╣ķāĮµ£ēõĖĆõĖ¬payload’╝īõ║ĵś»µłæõ╗¼ÕÅ»õ╗źÕ£©payloadķćīķØóõ┐ØÕŁśµłæõ╗¼Ķć¬ÕĘ▒ńÜäµ¢ćµĪŻÕÅĘŃĆéµ»ÅÕĮōµłæõ╗¼ÕŠŚÕł░õĖĆõĖ¬LuceneńÜäµ¢ćµĪŻÕÅĘńÜ䵌ČÕĆÖ’╝īÕ░▒ĶāĮõ╗ÄĶĘ│ĶĘāĶĪ©õĖŁµ¤źµēŠÕł░µłæõ╗¼Ķć¬ÕĘ▒ńÜäµ¢ćµĪŻÕÅĘŃĆé
- PayloadõĖ╗Ķ”üµ£ēõ╗źõĖŗÕćĀń¦Źńö©µ│Ģ’╝Ü
| //ÕŻ░µśÄõĖĆõĖ¬ńē╣µ«ŖńÜäÕ¤¤ÕÆīńē╣µ«ŖńÜäĶ»Ź
┬Ā public static final String ID_PAYLOAD_FIELD = "_ID"; public static final String ID_PAYLOAD_TERM = "_ID"; public static final Term ID_TERM = new Term(ID_PAYLOAD_TERM, ID_PAYLOAD_FIELD); //ÕŻ░µśÄõĖĆõĖ¬ńē╣µ«ŖńÜäTokenStream’╝īÕ«āÕŬńö¤µłÉõĖĆõĖ¬Ķ»Ź(Term)’╝īÕ░▒µś»ķéŻõĖ¬ńē╣µ«ŖńÜäĶ»Ź’╝īÕ£©ńē╣µ«ŖńÜäÕ¤¤ķćīķØóŃĆé static class SinglePayloadTokenStream extends TokenStream { ┬Ā┬Ā┬Ā private Token token; ┬Ā┬Ā┬Ā private boolean returnToken = false; ┬Ā┬Ā┬Ā SinglePayloadTokenStream(String idPayloadTerm) { ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā char[] term = idPayloadTerm.toCharArray(); ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā token = new Token(term, 0, term.length, 0, term.length); ┬Ā┬Ā┬Ā } ┬Ā┬Ā┬Ā void setPayloadValue(byte[] value) { ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā token.setPayload(new Payload(value)); ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā returnToken = true; ┬Ā┬Ā┬Ā } ┬Ā┬Ā┬Ā public Token next() throws IOException { ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā if (returnToken) { ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā returnToken = false; ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā return token; ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā } else { ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā return null; ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā } ┬Ā┬Ā┬Ā } } //Õ»╣õ║ĵ»ÅõĖĆń»ćµ¢ćµĪŻ’╝īķāĮĶ«®Õ«āÕīģÕɽĶ┐ÖõĖ¬ńē╣µ«ŖńÜäĶ»Ź’╝īÕ£©ńē╣µ«ŖńÜäÕ¤¤ķćīķØó SinglePayloadTokenStream singlePayloadTokenStream = new SinglePayloadTokenStream(ID_PAYLOAD_TERM); singlePayloadTokenStream.setPayloadValue(long2bytes(id)); doc.add(new Field(ID_PAYLOAD_FIELD, singlePayloadTokenStream));//µ»ÅÕĮōÕŠŚÕł░õĖĆõĖ¬LuceneńÜäµ¢ćµĪŻÕÅʵŚČ’╝īķĆÜĶ┐ćõ╗źõĖŗńÜäµ¢╣Õ╝ÅÕŠŚÕł░payloadķćīķØóńÜäµ¢ćµĪŻÕÅĘ long id = 0; TermPositions tp = reader.termPositions(ID_PAYLOAD_TERM); boolean ret = tp.skipTo(docID); tp.nextPosition(); int payloadlength = tp.getPayloadLength(); byte[] payloadBuffer = new byte[payloadlength]; tp.getPayload(payloadBuffer, 0); id = bytes2long(payloadBuffer); tp.close(); |
┬Ā
┬Ā
- ┬Ā
- ┬Ā
- ÕĮ▒ÕōŹĶ»ŹńÜäĶ»äÕłå
- Õ£©SimilarityµŖĮĶ▒Īń▒╗õĖŁµ£ēÕćĮµĢ░public float scorePayload(byte [] payload, int offset, int length)┬Ā ÕÅ»õ╗źµĀ╣µŹ«payloadńÜäÕĆ╝ÕĮ▒ÕōŹĶ»äÕłåŃĆé
- ÕĮ▒ÕōŹĶ»ŹńÜäĶ»äÕłå
- ┬Ā
- Ķ»╗ÕÅ¢Õ¤¤ÕģāµĢ░µŹ«õ┐Īµü»ńÜäõ╗ŻńĀüÕ”éõĖŗ’╝Ü
|
┬Ā FieldInfos.read(IndexInput, String)
|
┬Ā
┬Ā
4.1.3. Õ¤¤(Field)ńÜäµĢ░µŹ«õ┐Īµü»(.fdt’╝ī.fdx)

- Õ¤¤µĢ░µŹ«µ¢ćõ╗Č(fdt):
- ń£¤µŁŻõ┐ØÕŁśÕŁśÕé©Õ¤¤(stored field)õ┐Īµü»ńÜ䵜»fdtµ¢ćõ╗Č
- Õ£©õĖĆõĖ¬µ«Ą(segment)õĖŁµĆ╗Õģ▒µ£ēsegment sizeń»ćµ¢ćµĪŻ’╝īµēĆõ╗źfdtµ¢ćõ╗ČõĖŁÕģ▒µ£ēsegment sizeõĖ¬ķĪ╣’╝īµ»ÅõĖĆķĪ╣õ┐ØÕŁśõĖĆń»ćµ¢ćµĪŻńÜäÕ¤¤ńÜäõ┐Īµü»
- Õ»╣õ║ĵ»ÅõĖĆń»ćµ¢ćµĪŻ’╝īõĖĆÕ╝ĆÕ¦ŗµś»õĖĆõĖ¬fieldcount’╝īõ╣¤ÕŹ│µŁżµ¢ćµĪŻÕīģÕɽńÜäÕ¤¤ńÜäµĢ░ńø«’╝īµÄźõĖŗµØźµś»fieldcountõĖ¬ķĪ╣’╝īµ»ÅõĖĆķĪ╣õ┐ØÕŁśõĖĆõĖ¬Õ¤¤ńÜäõ┐Īµü»ŃĆé
- Õ»╣õ║ĵ»ÅõĖĆõĖ¬Õ¤¤’╝īfieldnumµś»Õ¤¤ÕÅĘ’╝īµÄźńØƵś»õĖĆõĖ¬8õĮŹńÜäbyte’╝īµ£ĆõĮÄõĖĆõĮŹĶĪ©ńż║µŁżÕ¤¤µś»ÕÉ”ÕłåĶ»Ź(tokenized)’╝īÕĆƵĢ░ń¼¼õ║īõĮŹĶĪ©ńż║µŁżÕ¤¤µś»õ┐ØÕŁśÕŁŚń¼”õĖ▓µĢ░µŹ«Ķ┐śµś»õ║īĶ┐øÕłČµĢ░µŹ«’╝īÕĆƵĢ░ń¼¼õĖēõĮŹĶĪ©ńż║µŁżÕ¤¤µś»ÕÉ”Ķó½ÕÄŗń╝®’╝īÕåŹµÄźõĖŗµØźÕ░▒µś»ÕŁśÕé©Õ¤¤ńÜäÕĆ╝’╝īµ»öÕ”énew Field("title", "lucene in action", Field.Store.Yes, ŌĆ”)’╝īÕłÖµŁżÕżäÕŁśµöŠńÜäÕ░▒µś»"lucene in action"Ķ┐ÖõĖ¬ÕŁŚń¼”õĖ▓ŃĆé
- Õ¤¤ń┤óÕ╝Ģµ¢ćõ╗Č(fdx)
- ńö▒Õ¤¤µĢ░µŹ«µ¢ćõ╗ȵĀ╝Õ╝ŵłæõ╗¼ń¤źķüō’╝īµ»Åń»ćµ¢ćµĪŻÕīģÕɽńÜäÕ¤¤ńÜäõĖ¬µĢ░’╝īµ»ÅõĖ¬ÕŁśÕé©Õ¤¤ńÜäÕĆ╝ķāĮµś»õĖŹõĖƵĀĘńÜä’╝īÕøĀĶĆīÕ¤¤µĢ░µŹ«µ¢ćõ╗ČõĖŁsegment sizeń»ćµ¢ćµĪŻ’╝īµ»Åń»ćµ¢ćµĪŻÕŹĀńö©ńÜäÕż¦Õ░Åõ╣¤µś»õĖŹõĖƵĀĘńÜä’╝īķéŻõ╣łÕ”éõĮĢÕ£©fdtõĖŁĶŠ©Õł½µ»ÅõĖĆń»ćµ¢ćµĪŻńÜäĶĄĘÕ¦ŗÕ£░ÕØĆÕÆīń╗łµŁóÕ£░ÕØĆÕæó’╝īÕ”éõĮĢĶāĮÕż¤µø┤Õ┐½ńÜäµēŠÕł░ń¼¼nń»ćµ¢ćµĪŻńÜäÕŁśÕé©Õ¤¤ńÜäõ┐Īµü»Õæó’╝¤Õ░▒µś»Ķ”üÕƤÕŖ®Õ¤¤ń┤óÕ╝Ģµ¢ćõ╗ČŃĆé
- Õ¤¤ń┤óÕ╝Ģµ¢ćõ╗Čõ╣¤µĆ╗Õģ▒µ£ēsegment sizeõĖ¬ķĪ╣’╝īµ»Åń»ćµ¢ćµĪŻķāĮµ£ēõĖĆõĖ¬ķĪ╣’╝īµ»ÅõĖĆķĪ╣ķāĮµś»õĖĆõĖ¬long’╝īÕż¦Õ░ÅÕø║Õ«Ü’╝īµ»ÅõĖĆķĪ╣ķāĮµś»Õ»╣Õ║öńÜäµ¢ćµĪŻÕ£©fdtµ¢ćõ╗ČõĖŁńÜäĶĄĘÕ¦ŗÕ£░ÕØĆńÜäÕüÅń¦╗ķćÅ’╝īĶ┐ÖµĀĘÕ”éµ×£µłæõ╗¼µā│µēŠÕł░ń¼¼nń»ćµ¢ćµĪŻńÜäÕŁśÕé©Õ¤¤ńÜäõ┐Īµü»’╝īÕŬĶ”üÕ£©fdxõĖŁµēŠÕł░ń¼¼nķĪ╣’╝īńäČÕÉĵīēńģ¦ÕÅ¢Õć║ńÜälongõĮ£õĖ║ÕüÅń¦╗ķćÅ’╝īÕ░▒ÕÅ»õ╗źÕ£©fdtµ¢ćõ╗ČõĖŁµēŠÕł░Õ»╣Õ║öńÜäÕŁśÕé©Õ¤¤ńÜäõ┐Īµü»ŃĆé
- Ķ»╗ÕÅ¢Õ¤¤µĢ░µŹ«õ┐Īµü»ńÜäõ╗ŻńĀüÕ”éõĖŗ’╝Ü
|
┬Ā Document FieldsReader.doc(int n, FieldSelector fieldSelector)
|
┬Ā
4.1.3. Ķ»ŹÕÉæķćÅ(Term Vector)ńÜäµĢ░µŹ«õ┐Īµü»(.tvx’╝ī.tvd’╝ī.tvf)

Ķ»ŹÕÉæķćÅõ┐Īµü»µś»õ╗Äń┤óÕ╝Ģ(index)Õł░µ¢ćµĪŻ(document)Õł░Õ¤¤(field)Õł░Ķ»Ź(term)ńÜ䵣ŻÕÉæõ┐Īµü»’╝īµ£ēõ║åĶ»ŹÕÉæķćÅõ┐Īµü»’╝īµłæõ╗¼Õ░▒ÕÅ»õ╗źÕŠŚÕł░õĖĆń»ćµ¢ćµĪŻÕīģÕɽķéŻõ║øĶ»ŹńÜäõ┐Īµü»ŃĆé
- Ķ»ŹÕÉæķćÅń┤óÕ╝Ģµ¢ćõ╗Č(tvx)
- õĖĆõĖ¬µ«Ą(segment)ÕīģÕɽNń»ćµ¢ćµĪŻ’╝īµŁżµ¢ćõ╗ČÕ░▒µ£ēNķĪ╣’╝īµ»ÅõĖĆķĪ╣õ╗ŻĶĪ©õĖĆń»ćµ¢ćµĪŻŃĆé
- µ»ÅõĖĆķĪ╣ÕīģÕɽõĖżķā©Õłåõ┐Īµü»’╝Üń¼¼õĖĆķā©Õłåµś»Ķ»ŹÕÉæķćŵ¢ćµĪŻµ¢ćõ╗Č(tvd)õĖŁµŁżµ¢ćµĪŻńÜäÕüÅń¦╗ķćÅ’╝īń¼¼õ║īķā©Õłåµś»Ķ»ŹÕÉæķćÅÕ¤¤µ¢ćõ╗Č(tvf)õĖŁµŁżµ¢ćµĪŻńÜäń¼¼õĖĆõĖ¬Õ¤¤ńÜäÕüÅń¦╗ķćÅŃĆé
- Ķ»ŹÕÉæķćŵ¢ćµĪŻµ¢ćõ╗Č(tvd)
- õĖĆõĖ¬µ«Ą(segment)ÕīģÕɽNń»ćµ¢ćµĪŻ’╝īµŁżµ¢ćõ╗ČÕ░▒µ£ēNķĪ╣’╝īµ»ÅõĖĆķĪ╣ÕīģÕɽõ║åµŁżµ¢ćµĪŻńÜäµēƵ£ēńÜäÕ¤¤ńÜäõ┐Īµü»ŃĆé
- µ»ÅõĖĆķĪ╣ķ”¢Õģłµś»µŁżµ¢ćµĪŻÕīģÕɽńÜäÕ¤¤ńÜäõĖ¬µĢ░NumFields’╝īńäČÕÉĵś»õĖĆõĖ¬NumFieldsÕż¦Õ░ÅńÜäµĢ░ń╗ä’╝īµĢ░ń╗äńÜäµ»ÅõĖĆķĪ╣µś»Õ¤¤ÕÅĘŃĆéńäČÕÉĵś»õĖĆõĖ¬(NumFields - 1)Õż¦Õ░ÅńÜäµĢ░ń╗ä’╝īńö▒ÕēŹķØóµłæõ╗¼ń¤źķüō’╝īµ»Åń»ćµ¢ćµĪŻńÜäń¼¼õĖĆõĖ¬Õ¤¤Õ£©tvfõĖŁńÜäÕüÅń¦╗ķćÅÕ£©tvxµ¢ćõ╗ČõĖŁõ┐ØÕŁś’╝īĶĆīÕģČõ╗¢(NumFields - 1)õĖ¬Õ¤¤Õ£©tvfõĖŁńÜäÕüÅń¦╗ķćÅÕ░▒µś»ń¼¼õĖĆõĖ¬Õ¤¤ńÜäÕüÅń¦╗ķćÅÕŖĀõĖŖĶ┐Ö(NumFields - 1)õĖ¬µĢ░ń╗äńÜäµ»ÅõĖĆķĪ╣ńÜäÕĆ╝ŃĆé
- Ķ»ŹÕÉæķćÅÕ¤¤µ¢ćõ╗Č(tvf)
- µŁżµ¢ćõ╗ČÕīģÕɽõ║åµŁżµ«ĄõĖŁńÜäµēƵ£ēńÜäÕ¤¤’╝īÕ╣ČõĖŹÕ»╣µ¢ćµĪŻÕüÜÕī║Õłå’╝īÕł░Õ║Ģń¼¼ÕćĀõĖ¬Õ¤¤Õł░ń¼¼ÕćĀõĖ¬Õ¤¤µś»Õ▒×õ║ÄķéŻń»ćµ¢ćµĪŻ’╝īµś»ńö▒tvxõĖŁńÜäń¼¼õĖĆõĖ¬Õ¤¤ńÜäÕüÅń¦╗ķćÅõ╗źÕÅŖtvdõĖŁńÜä(NumFields - 1)õĖ¬Õ¤¤ńÜäÕüÅń¦╗ķćÅµØźÕå│Õ«ÜńÜäŃĆé
- Õ»╣õ║ĵ»ÅõĖĆõĖ¬Õ¤¤’╝īķ”¢Õģłµś»µŁżÕ¤¤ÕīģÕɽńÜäĶ»ŹńÜäõĖ¬µĢ░NumTerms’╝īńäČÕÉĵś»õĖĆõĖ¬8õĮŹńÜäbyte’╝īµ£ĆÕÉÄõĖĆõĮŹµś»µīćիܵś»ÕÉ”õ┐ØÕŁśõĮŹńĮ«õ┐Īµü»’╝īÕĆƵĢ░ń¼¼õ║īõĮŹµś»µīćիܵś»ÕÉ”õ┐ØÕŁśÕüÅń¦╗ķćÅõ┐Īµü»ŃĆéńäČÕÉĵś»NumTermsõĖ¬ķĪ╣ńÜäµĢ░ń╗ä’╝īµ»ÅõĖĆķĪ╣õ╗ŻĶĪ©õĖĆõĖ¬Ķ»Ź(Term)’╝īÕ»╣õ║ĵ»ÅõĖĆõĖ¬Ķ»Ź’╝īńö▒Ķ»ŹńÜäµ¢ćµ£¼TermText’╝īĶ»ŹķóæTermFreq(õ╣¤ÕŹ│µŁżĶ»ŹÕ£©µŁżµ¢ćµĪŻõĖŁÕć║ńÄ░ńÜäµ¼ĪµĢ░)’╝īĶ»ŹńÜäõĮŹńĮ«õ┐Īµü»’╝īĶ»ŹńÜäÕüÅń¦╗ķćÅõ┐Īµü»ŃĆé
- Ķ»╗ÕÅ¢Ķ»ŹÕÉæķćŵĢ░µŹ«õ┐Īµü»ńÜäõ╗ŻńĀüÕ”éõĖŗ’╝Ü
|
┬Ā TermVectorsReader.get(int docNum, String field, TermVectorMapper)
ÕøøŃĆüÕģĘõĮōµĀ╝Õ╝Å ┬Ā 4.2. ÕÅŹÕÉæõ┐Īµü» ÕÅŹÕÉæõ┐Īµü»µś»ń┤óÕ╝Ģµ¢ćõ╗ČńÜäµĀĖÕ┐ā’╝īõ╣¤ÕŹ│ÕÅŹÕÉæń┤óÕ╝ĢŃĆé ÕÅŹÕÉæń┤óÕ╝ĢÕīģµŗ¼õĖżķā©Õłå’╝īÕĘ”ķØ󵜻Ķ»ŹÕģĖ(Term Dictionary)’╝īÕÅ│ķØ󵜻ÕĆƵÄÆĶĪ©(Posting List)ŃĆé Õ£©LuceneõĖŁ’╝īĶ┐ÖõĖżķā©Õłåµś»Õłåµ¢ćõ╗ČÕŁśÕé©ńÜä’╝īĶ»ŹÕģĖµś»ÕŁśÕé©Õ£©tii’╝ītisõĖŁńÜä’╝īÕĆƵÄÆĶĪ©ÕÅłÕīģµŗ¼õĖżķā©Õłå’╝īõĖĆķā©Õłåµś»µ¢ćµĪŻÕÅĘÕÅŖĶ»Źķóæ’╝īõ┐ØÕŁśÕ£©frqõĖŁ’╝īõĖĆķā©Õłåµś»Ķ»ŹńÜäõĮŹńĮ«õ┐Īµü»’╝īõ┐ØÕŁśÕ£©prxõĖŁŃĆé
┬Ā 4.2.1. Ķ»ŹÕģĖ(tis)ÕÅŖĶ»ŹÕģĖń┤óÕ╝Ģ(tii)õ┐Īµü»
Õ£©Ķ»ŹÕģĖõĖŁ’╝īµēƵ£ēńÜäĶ»Źµś»µīēńģ¦ÕŁŚÕģĖķĪ║Õ║ŵÄÆÕ║ÅńÜäŃĆé
┬Ā 4.2.2. µ¢ćµĪŻÕÅĘÕÅŖĶ»Źķóæ(frq)õ┐Īµü»
µ¢ćµĪŻÕÅĘÕÅŖĶ»Źķóæµ¢ćõ╗ČķćīķØóõ┐ØÕŁśńÜ䵜»ÕĆƵÄÆĶĪ©’╝īµś»õ╗źĶĘ│ĶĘāĶĪ©ÕĮóÕ╝ÅÕŁśÕ£©ńÜäŃĆé
┬Ā 4.2.3. Ķ»ŹõĮŹńĮ«(prx)õ┐Īµü»
Ķ»ŹõĮŹńĮ«õ┐Īµü»õ╣¤µś»ÕĆƵÄÆĶĪ©’╝īõ╣¤µś»õ╗źĶĘ│ĶĘāĶĪ©ÕĮóÕ╝ÅÕŁśÕ£©ńÜäŃĆé
┬Ā 4.3. ÕģČõ╗¢õ┐Īµü» 4.3.1. µĀćÕćåÕī¢ÕøĀÕŁÉµ¢ćõ╗Č(nrm) õĖ║õ╗Ćõ╣łõ╝ܵ£ēµĀćÕćåÕī¢ÕøĀÕŁÉÕæó’╝¤õ╗Äń¼¼õĖĆń½ĀõĖŁńÜäµÅÅĶ┐░’╝īµłæõ╗¼ń¤źķüō’╝īÕ£©µÉ£ń┤óĶ┐ćń©ŗõĖŁ’╝īµÉ£ń┤óÕć║ńÜäµ¢ćµĪŻĶ”üµīēõĖĵ¤źĶ»óĶ»ŁÕÅźńÜäńøĖÕģ│µĆ¦µÄÆÕ║Å’╝īńøĖÕģ│µĆ¦Õż¦ńÜäµēōÕłå(score)ķ½ś’╝īõ╗ÄĶĆīµÄÆÕ£©ÕēŹķØóŃĆéńøĖÕģ│µĆ¦µēōÕłå(score)õĮ┐ńö©ÕÉæķćÅń®║ķŚ┤µ©ĪÕ×ŗ(Vector Space Model)’╝īÕ£©Ķ«Īń«ŚńøĖÕģ│µĆ¦õ╣ŗÕēŹ’╝īĶ”üĶ«Īń«ŚTerm Weight’╝īõ╣¤ÕŹ│µ¤ÉTermńøĖÕ»╣õ║ĵ¤ÉDocumentńÜäķćŹĶ”üµĆ¦ŃĆéÕ£©Ķ«Īń«ŚTerm WeightµŚČ’╝īõĖ╗Ķ”üµ£ēõĖżõĖ¬ÕĮ▒ÕōŹÕøĀń┤Ā’╝īõĖĆõĖ¬µś»µŁżTermÕ£©µŁżµ¢ćµĪŻõĖŁÕć║ńÄ░ńÜäµ¼ĪµĢ░’╝īõĖĆõĖ¬µś»µŁżTermńÜäµÖ«ķĆÜń©ŗÕ║”ŃĆ鵜ŠńäȵŁżTermÕ£©µŁżµ¢ćµĪŻõĖŁÕć║ńÄ░ńÜäµ¼ĪµĢ░ĶČŖÕżÜ’╝īµŁżTermÕ£©µŁżµ¢ćµĪŻõĖŁĶČŖķćŹĶ”üŃĆé Ķ┐Öń¦ŹTerm WeightńÜäĶ«Īń«Śµ¢╣µ│Ģµś»µ£ĆµÖ«ķĆÜńÜä’╝īńäČĶĆīÕŁśÕ£©õ╗źõĖŗÕćĀõĖ¬ķŚ«ķóś’╝Ü
┬Ā ńö▒õ║Äõ╗źõĖŖÕĤÕøĀ’╝īLuceneÕ£©Ķ«Īń«ŚTerm WeightµŚČ’╝īķāĮõ╝Üõ╣śõĖŖõĖĆõĖ¬µĀćÕćåÕī¢ÕøĀÕŁÉ(Normalization Factor)’╝īµØźÕćÅÕ░æõĖŖķØóõĖēõĖ¬ķŚ«ķóśńÜäÕĮ▒ÕōŹŃĆé µĀćÕćåÕī¢ÕøĀÕŁÉ(Normalization Factor)µś»õ╝ÜÕĮ▒ÕōŹķÜÅÕÉĵēōÕłå(score)ńÜäĶ«Īń«ŚńÜä’╝īLuceneńÜäµēōÕłåĶ«Īń«ŚõĖĆķā©ÕłåÕÅæńö¤Õ£©ń┤óÕ╝ĢĶ┐ćń©ŗõĖŁ’╝īõĖĆĶł¼µś»õĖĵ¤źĶ»óĶ»ŁÕÅźµŚĀÕģ│ńÜäÕÅéµĢ░Õ”éµĀćÕćåÕī¢ÕøĀÕŁÉ’╝īÕż¦ķā©ÕłåÕÅæńö¤Õ£©µÉ£ń┤óĶ┐ćń©ŗõĖŁ’╝īõ╝ÜÕ£©µÉ£ń┤óĶ┐ćń©ŗńÜäõ╗ŻńĀüÕłåµ×ÉõĖŁĶ»”Ķ┐░ŃĆé µĀćÕćåÕī¢ÕøĀÕŁÉ(Normalization Factor)Õ£©ń┤óÕ╝ĢĶ┐ćń©ŗµĆ╗ńÜäĶ«Īń«ŚÕ”éõĖŗ’╝Ü
Õ«āÕīģµŗ¼õĖēõĖ¬ÕÅéµĢ░’╝Ü
┬Ā õ╗ÄõĖŖķØóńÜäÕģ¼Õ╝Å’╝īµłæõ╗¼ń¤źķüō’╝īõĖĆõĖ¬Ķ»Ź(Term)Õć║ńÄ░Õ£©õĖŹÕÉīńÜäµ¢ćµĪŻµł¢õĖŹÕÉīńÜäÕ¤¤õĖŁ’╝īµĀćÕćåÕī¢ÕøĀÕŁÉõĖŹÕÉīŃĆéµ»öՔ鵣ēõĖżõĖ¬µ¢ćµĪŻ’╝īµ»ÅõĖ¬µ¢ćµĪŻµ£ēõĖżõĖ¬Õ¤¤’╝īÕ”éµ×£õĖŹĶĆāĶÖæµ¢ćµĪŻķĢ┐Õ║”’╝īÕ░▒µ£ēÕøøń¦ŹµÄÆÕłŚń╗äÕÉł’╝īÕ£©ķćŹĶ”üµ¢ćµĪŻńÜäķćŹĶ”üÕ¤¤õĖŁ’╝īÕ£©ķćŹĶ”üµ¢ćµĪŻńÜäķØ×ķćŹĶ”üÕ¤¤õĖŁ’╝īÕ£©ķØ×ķćŹĶ”üµ¢ćµĪŻńÜäķćŹĶ”üÕ¤¤õĖŁ’╝īÕ£©ķØ×ķćŹĶ”üµ¢ćµĪŻńÜäķØ×ķćŹĶ”üÕ¤¤õĖŁ’╝īÕøøń¦Źń╗äÕÉł’╝īµ»Åń¦Źµ£ēõĖŹÕÉīńÜäµĀćÕćåÕī¢ÕøĀÕŁÉŃĆé õ║ĵś»Õ£©LuceneõĖŁ’╝īµĀćÕćåÕī¢ÕøĀÕŁÉÕģ▒õ┐ØÕŁśõ║å(µ¢ćµĪŻµĢ░ńø«õ╣śõ╗źÕ¤¤µĢ░ńø«)õĖ¬’╝īµĀ╝Õ╝ÅÕ”éõĖŗ’╝Ü
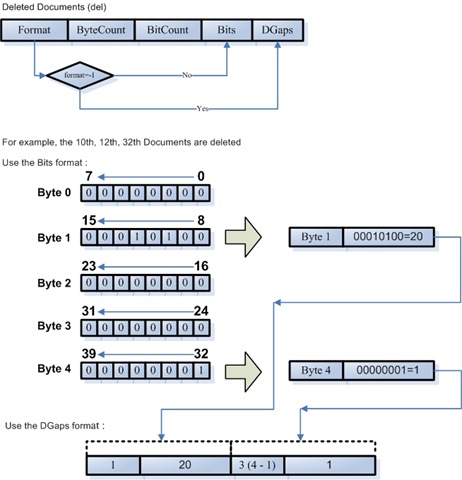
┬Ā 4.3.2. ÕłĀķÖżµ¢ćµĪŻµ¢ćõ╗Č(del) ┬Ā
┬Ā õ║öŃĆüµĆ╗õĮōń╗ōµ×ä
┬Ā ┬Ā ┬Ā ┬Ā
┬Ā Õż¦Õ«ČÕÅ»õ╗źķĆÜĶ┐ćń£ŗµ║Éõ╗ŻńĀü’╝īńøĖÕ║öńÜäReaderÕÆīWriterµØźõ║åĶ¦Żµ¢ćõ╗Čń╗ōµ×ä’╝īÕ░åµø┤õĖ║ķĆÅÕĮ╗ŃĆé |






- Õż¦Õ░Å: 7.7 KB



- 2012-02-01 16:50
- µĄÅĶ¦ł 6746
- Ķ»äĶ«║(0)
- Õłåń▒╗:ń╝¢ń©ŗĶ»ŁĶ©Ć
- µ¤źń£ŗµø┤ÕżÜ
ÕÅæĶĪ©Ķ»äĶ«║

-
MySQLNonTransientConnectionException: No operations allowed
2015-05-19 16:47 2258µ£ĆĶ┐æÕ£©Ķ░āĶ»Ģõ╝ÜÕÅæńÄ░ŌĆ£ No operations allow ... -
mysql µē¦ĶĪīĶ«ĪÕłÆõ╝śÕī¢
2013-04-07 17:46 1480õĖƵØĪń«ĆÕŹĢńÜäSQL Ķ»ŁÕÅźń½¤ĶŖ▒õ║å15.87┬Āsec’╝ī ┬Ā ... -
ThreadLocal Õ╝ĢĶĄĘńÜäÕåģÕŁśµ│äķ£▓
2012-10-18 17:48 2369µ£ĆĶ┐æÕ£©ńö©LOADRUNNERÕüܵƦĶāĮµĄŗĶ»Ģ’╝ī┬Ā Ķ┐ÉĶĪīÕćĀõĖ¬Õ░ŵŚČÕÉÄ’╝ī ... -
lucene ÕÅŹÕÉæń┤óÕ╝ĢÕĤńÉå
2012-07-20 12:47 1941luceneµś»õĖĆõĖ¬ķ½śµĆ¦ĶāĮńÜäÕģ©µ¢ćµÉ£ń┤óÕĘźÕģĘ’╝ī õĮ┐ńö©ÕÅŹÕÉæń┤óÕ╝Ģń╗ōµ×äŃĆé ... -
tomcat7Õ£©UBUNTUõĖŖĶć¬ÕŖ©ÕÉ»ÕŖ©
2012-06-11 12:55 2708õĖ║õ║åĶ«®tomcatĶć¬ÕŖ©ÕÉ»ÕŖ©ÕĮōńöĄĶäæķćŹĶĄĘµŚČ’╝ī õĮĀÕ┐ģķĪ╗µĘ╗ÕŖĀõĖĆõĖ¬Ķäܵ£¼’╝ī ... -
hadoopõĖŁńÜäWritableÕłåµ×É
2012-06-07 11:27 3333┬Ā hadoop Ķ”üõĮ┐õĖĆõĖ¬ń▒╗ĶāĮÕ║ÅõŠŗÕī¢’╝ī Ķ”üÕ«×ńÄ░Writabl ... -
Õ£©UBUNTUÕ«ēĶŻģNUTCH(ÕŹüõĖ¬ń«ĆÕŹĢńÜ䵣źķ¬ż)
2012-06-06 17:32 3951õĖŗķØóÕŹüõĖ¬µŁźķ¬żĶāĮÕ«ēĶŻģNutch, Õ╣ČõĖöĶāĮńł¼ĶĪīõĮĀńÜäńĮæń½Ö’╝ī ÕłøÕ╗║õĮĀĶć¬ ... -
EasyMock and IllegalStateException
2012-01-31 15:09 1296When writing a portlet and tryi ... -
Java EnumńÜäÕĤńÉå
2011-05-03 09:19 1773Java Enum ń▒╗Õ×ŗńÜäĶ»Łµ│Ģń╗ōµ×äÕ░Įń«ĪÕÆī java ń▒╗ńÜäĶ»Łµ│ĢõĖŹ ... -
ńö©JAXBõ╗ÄÕ»╣Ķ▒Īńö¤µłÉXML
2011-04-26 08:54 2917import java.io.FileOutputStream ... -
jdk6 WebServiceÕģźķŚ©
2011-03-10 23:04 3291┬Ā õĖĆŃĆü ┬Ā ┬Ā ┬Ā ┬Ā ┬Ā ┬ĀWeb Servicesń«Ćõ╗ŗ ... -
dom4jÕżäńÉåĶČģÕż¦XML
2010-12-26 23:35 4767Ķŗ▒µ¢ćÕĤµ¢ć ’╝Ü http://dom4j.sourceforge ... -
httpclient3 Ķć¬ÕŖ©ńÖ╗ķÖåµĘśÕ«Ø’╝ī Õ╝ĆÕ┐āńĮæ
2010-11-09 22:09 9919ÕēŹµÅÉ’╝Üķ£ĆĶ”üńö©Õł░ńÜäjavaÕīģ commons-httpclien ... -
LuceneÕ«×µŚČń┤óÕ╝Ģµ×äÕ╗║
2010-11-06 23:11 7370LuceneÕÅ»õ╗źÕó×ķćÅńÜäµĘ╗ÕŖĀõĖĆõ ... -
Õłåõ║½JavaÕ╣ČÕÅæµ£ĆõĮ│õ╣”ń▒ŹJava Concurrency in Practice JavaÕ╣ČÕÅæµ£ĆõĮ│õ╣”ń▒Ź õĖŗĶĮĮ
2010-10-21 08:31 13347ÕźĮõ╣ģµ▓Īµ£ēõĖŖµØźµø┤µ¢░Ķ┐ćõ║å’╝īµ£ĆĶ┐æÕ£©ÕŁ”õ╣Āń║┐ń©ŗµ▒ĀÕ«×ńÄ░’╝īÕÅéĶĆāõ║å┬Ā Tomc ... -
Spring Hibernate3 ķģŹńĮ« C3P0
2010-10-15 00:31 7488ńö▒õ║ÄHibernate3õĖŹµÄ©ĶŹÉõĮ┐ńö©DBCP’╝ī µēĆõ╗źµŖŖĶ┐׵ğµ▒ĀµŹóµłÉ ... -
Õ░åõŠØĶĄ¢ÕīģÕŖĀÕģźÕł░µ£¼Õ£░mavenÕ║ō
2010-07-22 16:47 2831Ķ”üÕ░åõŠØĶĄ¢ÕīģÕŖĀÕģźÕł░µ£¼Õ£░mavenÕ║ō mvn instal ... -
Maven DependencyĶ«ŠńĮ«’╝īĶ»”Ķ¦Ż’╝ü
2010-07-21 17:08 2456ńö©õ║åMaven’╝īµēĆķ£ĆńÜäJARÕīģÕ░ ... -
Inner Join with hibernate and HQL
2010-07-18 12:24 2107String queryStri ... -
ORACLE Õłåń╗ä µÄÆÕ║ÅÕć║ÕēŹķØóµ£ĆÕż¦ńÜäNĶĪī
2010-07-02 09:18 1591select┬Ā custid,carid,Cunote,INV ...
ńøĖÕģ│µÄ©ĶŹÉ
µ£ĆÕÉÄ’╝īĶÖĮńäČLuceneõĮ┐ńö©JavaĶ»ŁĶ©ĆÕåÖµłÉ’╝īõĮåµś»Õ╝ƵöŠµ║Éõ╗ŻńĀüńżŠÕī║ńÜäń©ŗÕ║ÅÕæśµŁŻÕ£©õĖŹµćłńÜäÕ░åõ╣ŗõĮ┐ńö©ÕÉäń¦Źõ╝Āń╗¤Ķ»ŁĶ©ĆÕ«×ńÄ░’╝łõŠŗÕ”é.net framework[14]’╝ē’╝īÕ£©ķüĄÕ«łLuceneń┤óÕ╝Ģµ¢ćõ╗ȵĀ╝Õ╝ÅńÜäÕ¤║ńĪĆõĖŖ’╝īõĮ┐ÕŠŚLuceneĶāĮÕż¤Ķ┐ÉĶĪīÕ£©ÕÉäń¦ŹÕÉäµĀĘńÜäÕ╣│ÕÅ░õĖŖ’╝īń│╗ń╗¤...
µ£ĆÕÉÄ’╝īĶÖĮńäČLuceneõĮ┐ńö©JavaĶ»ŁĶ©ĆÕåÖµłÉ’╝īõĮåµś»Õ╝ƵöŠµ║Éõ╗ŻńĀüńżŠÕī║ńÜäń©ŗÕ║ÅÕæśµŁŻÕ£©õĖŹµćłńÜäÕ░åõ╣ŗõĮ┐ńö©ÕÉäń¦Źõ╝Āń╗¤Ķ»ŁĶ©ĆÕ«×ńÄ░’╝łõŠŗÕ”é.net framework[14]’╝ē’╝īÕ£©ķüĄÕ«łLuceneń┤óÕ╝Ģµ¢ćõ╗ȵĀ╝Õ╝ÅńÜäÕ¤║ńĪĆõĖŖ’╝īõĮ┐ÕŠŚLuceneĶāĮÕż¤Ķ┐ÉĶĪīÕ£©ÕÉäń¦ŹÕÉäµĀĘńÜäÕ╣│ÕÅ░õĖŖ’╝īń│╗ń╗¤...
LuceneńÜäõĮ┐ńö©ĶĆģõĖŹķ£ĆĶ”üµĘ▒Õģźõ║åĶ¦Żµ£ēÕģ│Õģ©µ¢ćµŻĆń┤óńÜäń¤źĶ»å,õ╗ģõ╗ģÕŁ”õ╝ÜõĮ┐ńö©Õ║ōõĖŁńÜäõĖĆõĖ¬ń▒╗,õĮĀÕ░▒õĖ║õĮĀńÜäÕ║öńö©Õ«×ńÄ░Õģ©µ¢ćµŻĆń┤óńÜäÕŖ¤ĶāĮ. õĖŹĶ┐ćÕŹāõĖćÕł½õ╗źõĖ║Luceneµś»õĖĆõĖ¬Ķ▒Īgoogleķ鯵ĀĘńÜäµÉ£ń┤óÕ╝ĢµōÄ,LuceneńöÜĶć│õĖŹµś»õĖĆõĖ¬Õ║öńö©ń©ŗÕ║Å,Õ«āõ╗ģõ╗ģµś»õĖĆõĖ¬ÕĘźÕģĘ,...
Lucene µÉ£ń┤Ā ÕłåĶ»Ź ... ÕĖīµ£øÕż¦Õ«ČÕģ▒ÕÉīµÄóĶ«©.QQńŠż: 12966179 ńÄŗÕ░ŵ│ó 2008/12/10 ...µ£¼ń½ĀĶ┐śµČēÕÅŖLuceneń┤óÕ╝ĢńÜäÕåģķā©ń╗ōµ×ä’╝īńö©ÕżÜń║┐ń©ŗÕÆīÕżÜĶ┐øń©ŗĶ«┐ķŚ«LuceneµŚČńÜäķćŹńé╣ÕÆīķÜŠńé╣’╝īõ╗źÕÅŖķś▓µŁóÕ╣ČÕÅæń┤óÕ╝Ģõ┐«µö╣ńÜäķöüµ£║ÕłČĶ┐Öõ║øÕåģÕ«╣ŃĆé
// IndexFileDeleter deleterµś»IndexWriterń▒╗ńÜäõĖĆõĖ¬ń¦üµ£ēńÜ䵳ÉÕæśÕÅśķćÅ’╝īÕ«āÕ£©org.apache.lucene.indexÕīģķćīķØó’╝īõĖ╗Ķ”üÕ»╣ÕłĀķÖżń┤óÕ╝Ģµ¢ćõ╗ČĶ┐øĶĪīÕ«×ńÄ░ÕÆīń«ĪńÉå deleter = new IndexFileDeleter(directory, deletionPolicy == null ...
### ÕĆƵÄÆń┤óÕ╝ĢµĘ▒Õģźķ¬©ķ½ō - #### ÕĆƵÄÆń┤óÕ╝ĢńÜäÕĤńÉåõ╗źÕÅŖÕ«āµś»ńö©µØźĶ¦ŻÕå│Õō¬õ║øķŚ«ķóś’╝łĶ░łĶ░łõĮĀ...- #### ń┤óÕ╝Ģµ¢ćõ╗ČńÜäÕåģķā©ń╗ōµ×ä’╝ł.tipÕÆī.timµ¢ćõ╗ČÕåģķā©µĢ░µŹ«ń╗ōµ×ä’╝ē - #### FSTÕ£©LuceneńÜäĶ»╗ÕåÖĶ┐ćń©ŗ’╝łLuceneµ║ÉńĀüÕ«×ńÄ░’╝ē ....................
LuceneńÜäõĮ┐ńö©ĶĆģõĖŹķ£ĆĶ”üµĘ▒Õģźõ║åĶ¦Żµ£ēÕģ│Õģ©µ¢ćµŻĆń┤óńÜäń¤źĶ»å,õ╗ģõ╗ģÕŁ”õ╝ÜõĮ┐ńö©Õ║ōõĖŁńÜäõĖĆõĖ¬ń▒╗,õĮĀÕ░▒õĖ║õĮĀńÜäÕ║öńö©Õ«×ńÄ░Õģ©µ¢ćµŻĆń┤óńÜäÕŖ¤ĶāĮ. õĖŹĶ┐ćÕŹāõĖćÕł½õ╗źõĖ║Luceneµś»õĖĆõĖ¬Ķ▒Īgoogleķ鯵ĀĘńÜäµÉ£ń┤óÕ╝ĢµōÄ,LuceneńöÜĶć│õĖŹµś»õĖĆõĖ¬Õ║öńö©ń©ŗÕ║Å,Õ«āõ╗ģõ╗ģµś»õĖĆõĖ¬ÕĘźÕģĘ,...
Ķ»źń│╗ń╗¤Õł®ńö©õ║åLuceneÕ╝║Õż¦ńÜäÕģ©µ¢ćµÉ£ń┤óÕ╝ĢµōÄÕŖ¤ĶāĮ’╝īĶāĮÕż¤Õ»╣Õż¦ķćÅńÜäÕģ¼õ║żõ┐Īµü»Ķ┐øĶĪīµ£ēµĢłńÜäń┤óÕ╝ĢÕÆīµÉ£ń┤ó’╝īµÅÉõŠøÕ┐½ķƤÕćåńĪ«ńÜ䵤źĶ»óń╗ōµ×£ŃĆ鵌ĀĶ«║µś»ÕŁ”ńö¤Ķ┐śµś»Õ╝ĆÕÅæĶĆģ’╝īķāĮÕÅ»õ╗źķĆÜĶ┐浣żń│╗ń╗¤µĘ▒ÕģźńÉåĶ¦ŻÕ╣ČÕ«×ĶĘĄÕ”éõĮĢÕ£©JavańÄ»ÕóāõĖŗõĮ┐ńö©LuceneĶ┐øĶĪīµĢ░µŹ«µŻĆń┤óŃĆé...
LuceneķØ×ÕĖĖÕżŹµØé’╝īõĮĀķ£ĆĶ”üµĘ▒ÕģźńÜäõ║åĶ¦ŻµŻĆń┤óńøĖÕģ│ń¤źĶ»åµØźńÉåĶ¦ŻÕ«āµś»Õ”éõĮĢÕĘźõĮ£ńÜäŃĆé Elasticsearchõ╣¤µś»õĮ┐ńö©Javań╝¢ÕåÖÕ╣ČõĮ┐ńö©LuceneµØźÕ╗║ń½ŗń┤óÕ╝ĢÕ╣ČÕ«×ńÄ░µÉ£ń┤óÕŖ¤ĶāĮ’╝īõĮåµś»Õ«āńÜäńø«ńÜ䵜»ķĆÜĶ┐ćń«ĆÕŹĢĶ┐×Ķ┤»ńÜäRESTful APIĶ«®Õģ©µ¢ćµÉ£ń┤óÕÅśÕŠŚń«ĆÕŹĢÕ╣ČķÜÉĶŚÅ...
Õ£©Õ¤║õ║ÄÕŁŚĶĪ©ńÜäÕģ©µ¢ćń┤óÕ╝Ģµ¢╣ķØó’╝īµ£¼µ¢ćµÅÉÕć║õ║åõĖĆń¦Źµö╣Ķ┐øńÜäÕĆƵÄÆń┤óÕ╝Ģń╗ōµ×ä’╝īÕÉīõ╝Āń╗¤ń┤óÕ╝Ģń╗ōµ×äńøĖµ»ö’╝īµø┤õŠ┐õ║Äń┤óÕ╝ĢńÜäµ×äÕ╗║ŃĆüń╗┤µŖżŃĆüµø┤µ¢░ŃĆéµ£¼µ¢ćńÜäķćŹńé╣µöŠÕ£©õ║åÕģ©µ¢ćµŻĆń┤óµŖƵ£»ńÜäÕ║öńö©õĖŖ’╝īÕ»╣Õ”éõĮĢÕł®ńö©µ¢░µŖƵ£»ŃĆüµö╣Õ¢äµŻĆń┤óń│╗ń╗¤ńÜäń╗ōµ×äŃĆüµÅÉķ½śµŻĆń┤óń│╗ń╗¤ńÜä...
Ķ»┤Õ╣▓Õ░▒Õ╣▓’╝īµłæÕ¢£µ¼óĶ»╗ÕÅ¢õ╗ŻńĀüńÜäµ¢╣Õ╝ŵś»µīēńģ¦µāģµÖ»ķśģĶ»╗’╝īµ»öÕ”éÕ£©LuceneõĖŁĶʤĶĖ¬ń┤óÕ╝ĢńÜäĶ┐ćń©ŗ’╝īĶʤĶĖ¬µÉ£ń┤óńÜäĶ┐ćń©ŗ’╝īµ»öÕ”éÕ£©HadoopõĖŁ’╝īĶʤĶĖ¬ÕåÖÕģźµ¢ćõ╗ČńÜäĶ┐ćń©ŗ’╝īĶʤĶĖ¬Map-ReduceńÜäĶ┐ćń©ŗ’╝īõ║ĵś»Õ£©OpenstackõĖŁÕå│Õ«ÜĶʤĶĖ¬ĶÖܵŗ¤µ£║ÕłøÕ╗║ńÜäµĢ┤õĖ¬Ķ┐ćń©ŗÕźĮÕ£©...
Ōöé Ōöé µĘ▒ÕģźńÉåĶ¦ŻJavaÕåģÕŁśµ©ĪÕ×ŗ.pdf Ōöé Ōöé Ōöé ŌööŌöĆĶ»ŠÕÉÄĶĄäµ¢Ö Ōöé Ōö£ŌöĆń¼öĶ«░ Ōöé Ōöé µĘśµĘśÕĢåÕ¤Ä_day20_Ķ»ŠÕĀéń¼öĶ«░.docx Ōöé Ōöé Ōöé ŌööŌöĆĶ¦åķóæ Ōöé 07-õĮ┐ńö©JedisĶ┐׵ğķøåńŠżµōŹõĮ£.avi Ōöé 00-õ╗ŖµŚźÕż¦ń║▓.avi Ōöé 01-RDBµīüõ╣ģÕī¢µ¢╣Õ╝Å.avi Ōöé 02...
µĢ░µŹ«Õ║ōÕ╝ĆÕÅæÕ¤║ńĪĆŃĆüMicrosoft SQLServerÕ¤║ńĪĆŃĆüSQLĶ»ŁĶ©ĆÕ¤║ńĪĆŃĆüń┤óÕ╝ĢŃĆüõ║ŗÕŖĪŃĆüSQLĶ»ŁĶ©Ćķ½śń║¦µŖƵ£»’╝łń®║ÕĆ╝ÕżäńÉåŃĆüĶüÜÕÉłõĖÄÕłåń╗äŃĆüµĢ░µŹ«ÕłåķĪĄŃĆüUnionŃĆüµŚźµ£¤ÕćĮµĢ░ŃĆüń▒╗Õ×ŗĶĮ¼µŹóÕćĮµĢ░ŃĆüµĄüµÄ¦ÕćĮµĢ░ŃĆüĶĪ©Ķ┐׵ğŃĆüÕŁÉµ¤źĶ»óŃĆüÕŁśÕé©Ķ┐ćń©ŗŃĆüĶ¦”ÕÅæÕÖ©’╝ēŃĆüµĢ░µŹ«Õ║ō...